딥러닝
Knowledge Distillation 개요
- -
Knowledge Distillation 의 정의
Knowledge Distillation is a process of distilling or transferring the knowledge from a large, cumbersome (다루기 어려운) model(s) to a lighter, easier-to-deploy single model, without significant loss in performance
KD 는 퍼포먼스의 손실을 최소화하면서 크고 복잡한 모델로부터 작은 모델로 Knowledge 를 전파하는 것을 의미합니다.
큰 모델에서 나오는 성능을 작은 플랫폼에서 돌아가는 모델에 어떻게 적용할 수 있을까 ? 에 관련한 연구들은 다양한 방면에서 진행되고 있습니다. 예를 들어 다음과 같은 방법들이 있습니다.
- Pruning : 네트워크에서 필요없는 부분을 잘라내서 간단하게 만드는 것.
- Quantization : ex. 파라미터 weight 들이 float64 (8 byte)를 쓴다고 할 때, 이를 정수화하여 1 byte 로 만들면 같은 모델의 아키텍쳐를 가지면서도 연산량과 연산 시간이 줄어든다.
- Neural Architecture Search (NAS) : 모델의 가장 효율적인 구조를 학습을 통해서 찾는 방법
- Knowledge Distillation
What is knowledge ?
그러면 모델에서 "지식" 은 과연 무엇일까요? 가장 쉽게 말하자면, 모델의 지식은 모델의 파라미터입니다. 모델의 파라미터는 결국 어떤 signal 이 왔을 때 내가 어떻게 weight 을 줘서 곱하고 곱한 activation 들을 어떻게 조합할 것인지에 관한 것들입니다. 이 파라미터들이 결국 지식이라는 것입니다.
파라미터들은 단순히 숫자가 아니라 결국 필터들을 어떻게 조합할 것인지에 관한 정보입니다.
혹은 input 이 들어왔을 때 output 이 나오는 일련의 과정들 (input vector 가 output vector 로 어떻게 mapping 이 되는가 ?) 을 우리는 knowledge 라고 볼 수도 있습니다.
따라서 KD 의 목적을 쉽게 설명하자면, 큰 함수와 동일한 결과가 나오는 작은 함수를 만드는 것이라고 할 수 있습니다.
Distilling the Knowledge in a Neural Network
"Distillation" 이란 용어를 처음 사용한 것은 2014 년 NIPS 에 발표된 논문인 "Distilling the Knowledge in a Neural Network" 입니다.
이 논문에서 궁극적으로 증명하고자 하는 것은, KD 를 통해서 student 모델을 학습을 하면 단순히 student 모델을 처음부터 학습시키는 것 보다 훨씬 더 효율적이라는 것입니다.
이 논문이 발표되었을 때의 학계의 흐름에 관해 잠깐 말씀드리자면, AlexNet, GoogLeNet 등이 제안되며 backbone 네트워크의 발전이 있어왔지만 2014년 즈음은 정체기였습니다. DenseNet 등이 제안되었지만 ResNet 의 패러다임을 조금 개선한 정도였지, 비약적인 성능의 발전이 이루어지지는 않았었습니다.
그래서 사람들은 ensemble 방식을 도입하기 시작했습니다. 앙상블 방식은 여러 개의 네트워크를 사용해서 최적의 결과값을 도출하는 방법입니다. 그러나 이 방식은 성능을 높일 수는 있지만 계산량이 너무 많다는 단점이 있습니다. 학습하기도 어렵구요.
그래서 이런 큰 모델의 단점은 극복하고, 성능 향상은 그대로 이루기 위해서 Distillation 이 제안되었다고 할 수 있습니다.
KD 의 전체적인 흐름은 다음과 같습니다.
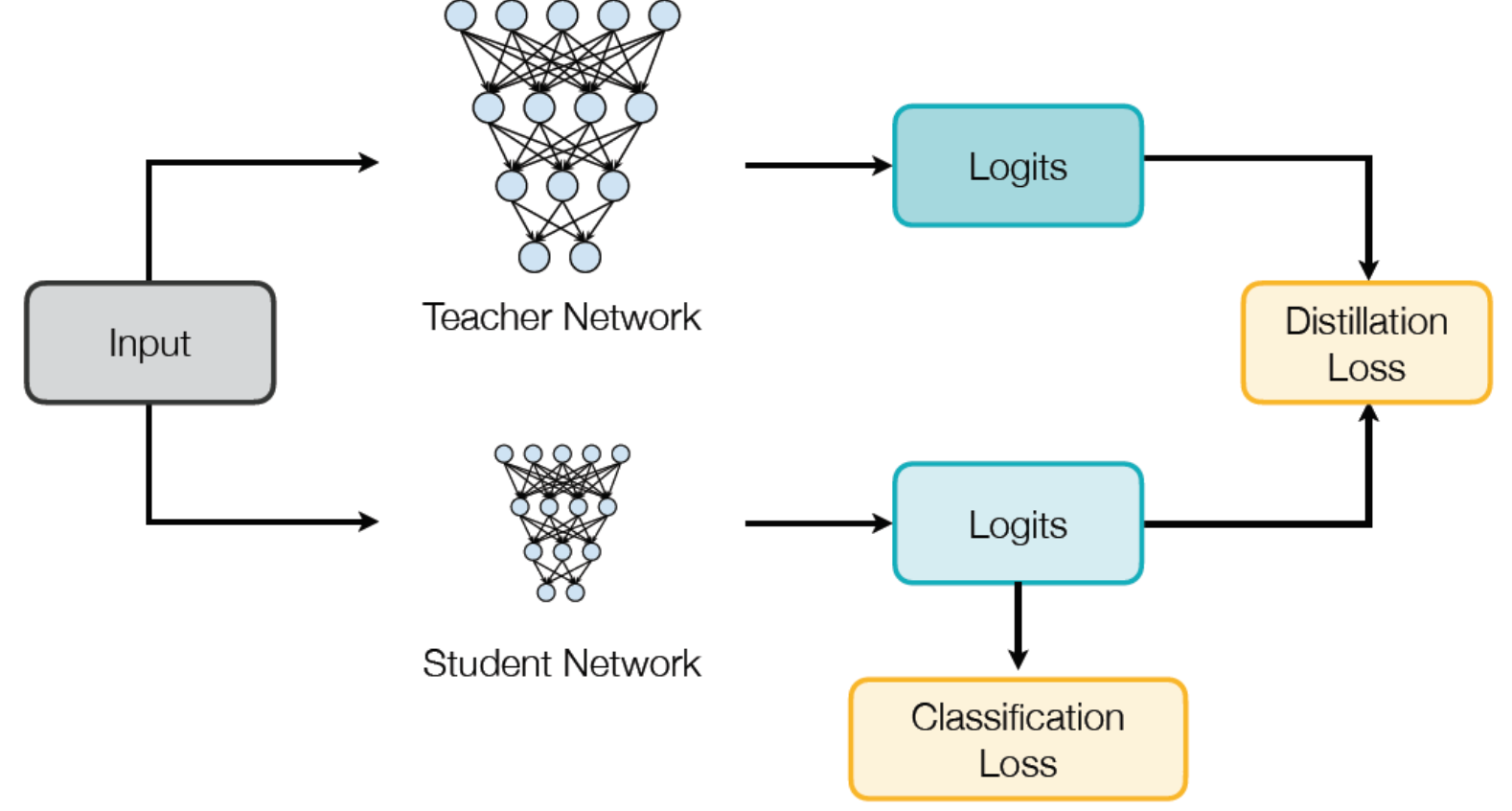
작은 모델을 학습할 때 Classification loss 와 Distillation loss 를 모두 사용합니다. Classification loss 는 정답과의 cross entropy 이고, Distillation loss 는 "작은 모델이 predict 한 distribution 이 큰 모델과 비슷한지 / 아닌지" 입니다.
Distillation 이 지식을 전파하거나, 내려준다거나 - 라고 생각할 수 있지만, 사실은 "작은 모델이 큰 모델을 따라가게끔" 하는 것이 KD 입니다.
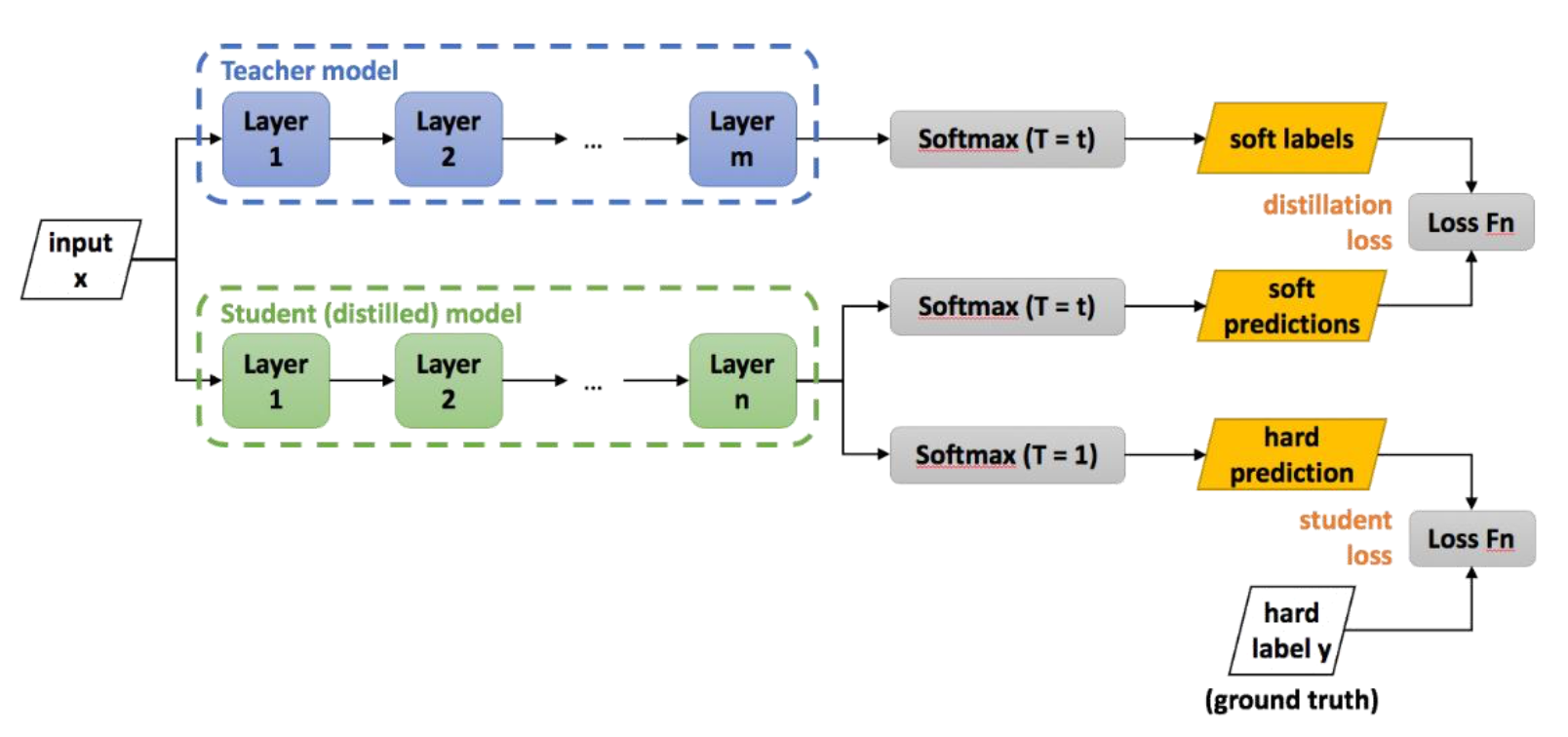
이때 Distillation loss 는 Soft label 과 Soft prediction 의 cross - entropy 라고 할 수 있습니다. 그러면 여기서 soft 란 무엇일까요 ?
Distillation Loss - Soft Target (Soft Target)
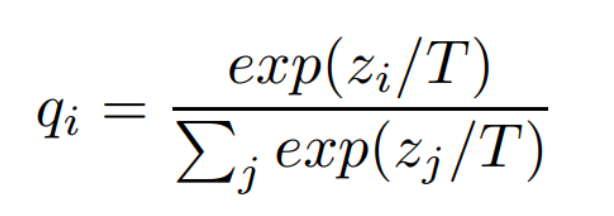
input 을 집어 넣으면 teacher 최종단에서 logit 들이 나옵니다. 이 logit 을 softmax 를 해서 확률분포를 구해준 후 GT 와 cross entropy 를 구하는 것이 일반적인 학습 방법 (Classification loss) 입니다.
그런데 이 논문에서는 조금 더 나은 방법이 있다고 제안합니다.
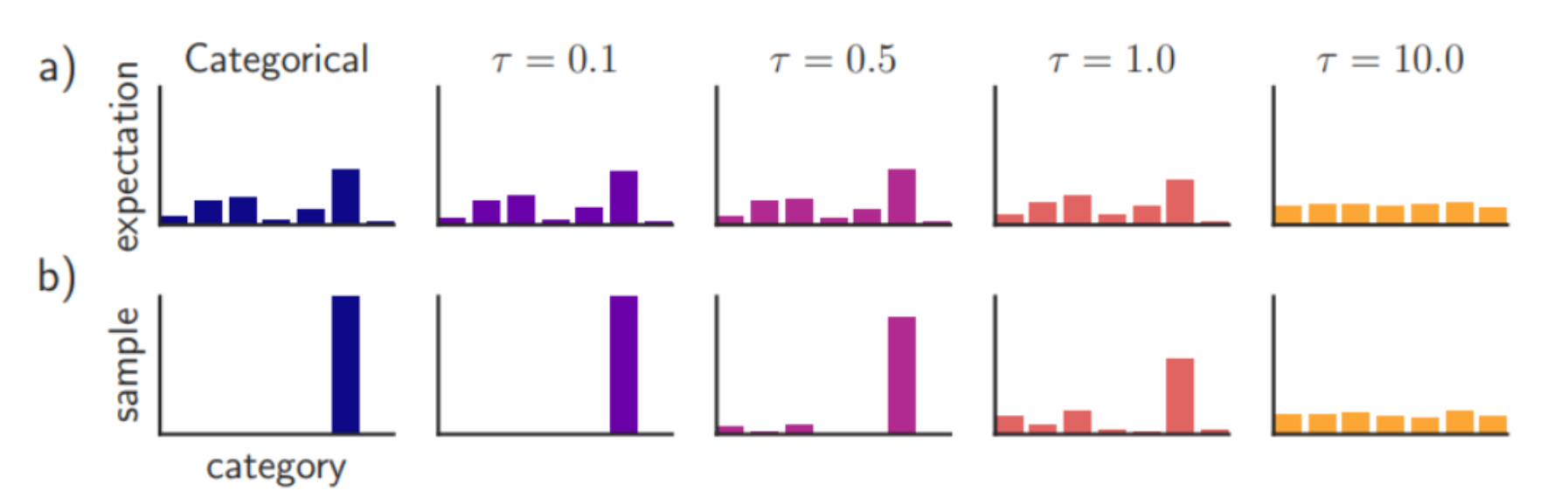
나온 Logit 값을 그대로 쓰느냐, 아니면 T (Temperature) 로 나눠 주느냐에 따라서 결과가 달라진다는 것입니다. 위 식에서 T = 1 이면 우리가 알고 있는 Softmax 값입니다.
T 가 무한대이면 모든 logit 들이 1/n 의 값을 갖는 uniform distribution 이 됩니다. 이 T 를 활용함으로써 다음과 같은 효과가 나타납니다.
- Increase entropy
- Increase dark knowledge
T 를 높일 수록 logit 들 간의 격차가 줄어들게 됩니다.

2는 3,7 과 모양의 유사성이 있다고 할 수 있습니다. 그렇기 때문에 discrete 하게 student 를 학습시키는 것 보다 generality 를 같이 학습시키는 것이 성능 향상에 도움이 된다고 이 논문은 주장합니다.
위 내용은 경희대학교 소프트웨어융합학과 황효석 교수님의 2023년 <심층신경망을 이용한 로봇 인지> 수업 내용을 요약한 것입니다.
'딥러닝' 카테고리의 다른 글
| Self - Supervised Learning : Pretext Task (0) | 2023.11.09 |
|---|---|
| 다양한 Knowledge Distillation 방법들 : 1. Response - based KD (1) | 2023.10.16 |
| 큰 이미지에서 동작하는 ViT : Swin Transformer (0) | 2023.10.04 |
| 어텐션을 비전에 : ViT (Vision Transformer) (0) | 2023.10.02 |
| Transformer 완전 정복하기😎 (0) | 2023.09.25 |
Contents
소중한 공감 감사합니다