딥러닝
Self - Supervised Learning : Pretext Task
- -
Self-supervised learning 의 필요성과 기능
Supervised Learning 이 발전함에 따라서, 필연적으로 Self-Supervised Learning 이 각광을 받게 되었습니다.
DNN 은 기적같은 성과를 내었지만 이를 위해서는 상당히 많은 양의 Labeled 데이터가 필요했습니다.
Annotation 은 상당히 비용이 많이 들고, 돈이 있다고 해서 모두 할 수 있는 것도 아닙니다. 예를 들어 Medical Data 같은 경우 전문성이 필요합니다.
Self-Supervised Learning 을 처음 들었을 때 , "스스로 Annotation 을 해 주는 건가 ?" 라는 생각이 들 수 있습니다. 그렇다기보다는, label 자체를 "누군가가 애써서 만들지 않아도 된다" 라고 생각하면 됩니다. Human annotation 없이, label 을 input 스스로 만들어 낼 수 있다는 것이 핵심입니다.
그러면, Annotation 을 안 해도 된다면 어떤 문제들을 풀 수 있을까요 ?
예를 들어 Super Resolution 이 있을 수 있습니다. 400 x 400 짜리 이미지가 있다고 할 때, 이 이미지를 줄이면 200 x 200 이미지를 만들 수 있습니다. 이 이미지를 다시 키우는 task 를 수행한다고 할 때, 우리는 이미지를 줄였기 때문에 원본 이미지를 가지고 있습니다. 정답을 가지고 있으므로 따로 정답을 만들 필요가 없습니다.
또, Colorization 이 있습니다. 흑백 이미지에 색상을 부여하는 알고리즘을 만들고 싶을 때, 컬러 이미지를 흑백으로 만들고 복원된 이미지를 원본과 비교하면 됩니다.
하지만,
Self-supervised learning 을 할 때 그 task 만을 위해서 학습을 하는 경우도 있기는 합니다. impainting 메소드를 만들어야지, 라고 하는 경우도 있습니다.
하지만 대부분의 Self-supervised learning 의 목적은 "그 task 를 잘 하기 위해" 하는 것이 아니라, 결국 High - level Representation 을 annotation 없이 학습하기 위해서 하는 것입니다.
Self-supervised learning 을 사용하면 Feature 들을 잘 뽑아내는 네트워크를 학습 할 수 있습니다. 그리고 이 네트워크를 Fine Tuning, Linear Probing 등을 사용해서 다른 task 에 사용할 수 있도록 가공하는 것입니다.
Pretext Task
처음에 Self-supervised learning 이 나왔을 때는 Pretext Task 에 대한 연구가 많이 이루어졌습니다. (2015~2018) 그 다음에는 Contrastive Learning 이 많이 각광을 받았고요 (2019~2021), 지금은 Masked Autoencoder 가 대세를 이루고 있습니다.
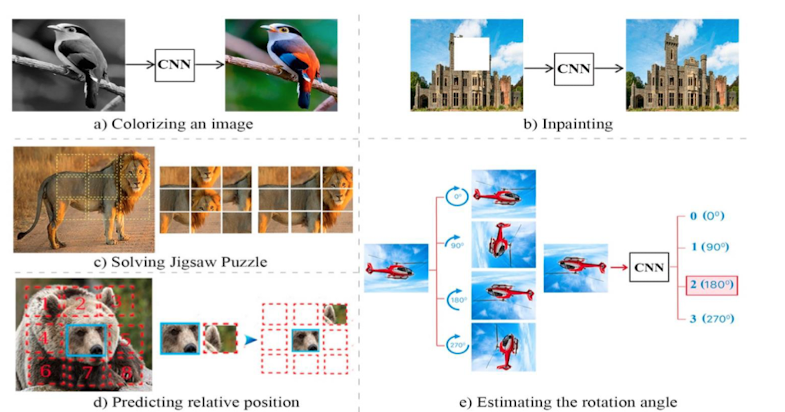
Pretext 는 "미리 Context 를 정해놓았다" 라고 이해하면 좋을 것 같습니다. 따라서 Pretext Task 는 Labelling 되지 않은 데이터에서 정답을 어떻게 설계할 것인가 ? 에 관한 문제입니다.
X를 데이터, Z(X)를 representation, Y를 Pretext label, I를 두 랜덤변수의 mutual information이라고 하면 다음과 같이 정의할 수 있습니다.
- Pretext Task
- Maximize I(Z(X);Y)
- ex) prediction, 직소 퍼즐, colorization, rotation
- Invariance
- Maximize I(Z(X1);Z(X2))
- ex) clustering, consistency, contrastive
- Generation
- Maximize I(Z(X~);X), X~는 X의 perturbed version
- ex) masked autoencoder, sequential prediction

위 내용은 경희대학교 소프트웨어융합학과 황효석 교수님의 2023년 <심층신경망을 이용한 로봇 인지> 수업 내용을 요약한 것입니다.
'딥러닝' 카테고리의 다른 글
| Contrastive Learning : Moco (Momentum Contrast) (0) | 2023.11.16 |
|---|---|
| Self - Supervised Learning : Contrastive Learning (1) | 2023.11.09 |
| 다양한 Knowledge Distillation 방법들 : 1. Response - based KD (1) | 2023.10.16 |
| Knowledge Distillation 개요 (0) | 2023.10.16 |
| 큰 이미지에서 동작하는 ViT : Swin Transformer (0) | 2023.10.04 |
Contents
소중한 공감 감사합니다