딥러닝
큰 이미지에서 동작하는 ViT : Swin Transformer
- -
ViT 의 한계점
Self-Attention 을 Computer Vision 도메인에 적용한 ViT 는 Classification 분야에서 SOTA 의 성능을 보여주었습니다. 다만 ViT 는 Classification 문제만 다룰 수 있다는 한계점이 있었습니다. 또한, ViT는 NLP 의 transformer 를 거의 그대로 가져다 썼기 때문에, Vision 문제 처리에 특화된 transformer 구조를 제안할 수 있지 않을까 ? 하는 제안도 있었습니다.
Computational Cost 가 크다는 문제점도 있고요.
Swin Transformer 의 제안
Swin Transformer 는 이런 단점을 극복하기 위해서 만들어졌습니다. 이는 계층적인 (Hierarchical) 트랜스포머입니다.
Shifted Windows transformer 라서 Swin 입니다.
What is Swin ?
- A general-purpose backbone for computer vision
- general-purpose backbone 이란, 약간의 수정을 통해서 detection , classificiation 등 다양한 task 에 활용할 수 있도록 고안된 네트워크입니다.
- The authors propose a hierarchical transformer whose representation is computed with Shited Windows
- Swin Transformer 에서는 패치의 사이즈가 계속 계층적으로 달라집니다.
- 처음에는 패치의 사이즈가 작았다가 , 점점 더 커집니다.
- 패치 사이즈가 작을 때는 receptive field 가 작으니까 좀 더 디테일한 특징들을 추출할 수 있고, 패치 사이즈가 크면 large scale 의 특징들에 집중할 수 있습니다.
- 이런 점들이 Vision Task 에 적합하다고 하는 것입니다.
- Shifted Window 를 도입하며, self-attention 의 단점들을 엄청나게 극복할 수 있었고, 따라서 이제는 큰 사이즈의 이미지에도 ViT 를 적용할 수 있게 되었습니다.

Swin Transformer 의 패치의 최초의 크기는 4x4 입니다. ViT 에서 사용하는 16x16 사이즈 패치에 비하면 조금 작습니다.
이 패치들이 이루고 있는 그룹을 Window 라고 합니다.
그러면 왜 굳이 Window 라는 개념을 도입했을까요 ? Self-attention 은 그럼 패치가 하는 걸까요, 아니면 윈도우가 하는 걸까요 ?
ViT 에서는 Self-attention 의 단위가 Global 이었습니다. 모든 패치들끼리 Similarity Score 를 만들어서 Value 를 계산했습니다. 그에 반해 Swin Transformer 에서는 Attention 을 하는 바운더리가 윈도우 단위입니다.
즉, 패치끼리 Attention 을 하기는 하는데, Window 내부에 있는 패치들끼리만 Attention 을 한다는 것입니다. 이를 통해서 계산량이 감소했습니다.
Swin Transformer 의 장점
- Focus on different scale in locality
- Detail : detection, segmentation
- Global : Scene understanding, classification
Swin Transformer 는 패치의 크기를 다변화 시키면서 다양한 Feature 들을 계산해 낼 수 있게 되었습니다.
다음의 식을 통해 연산량의 차이를 비교할 수 있습니다.
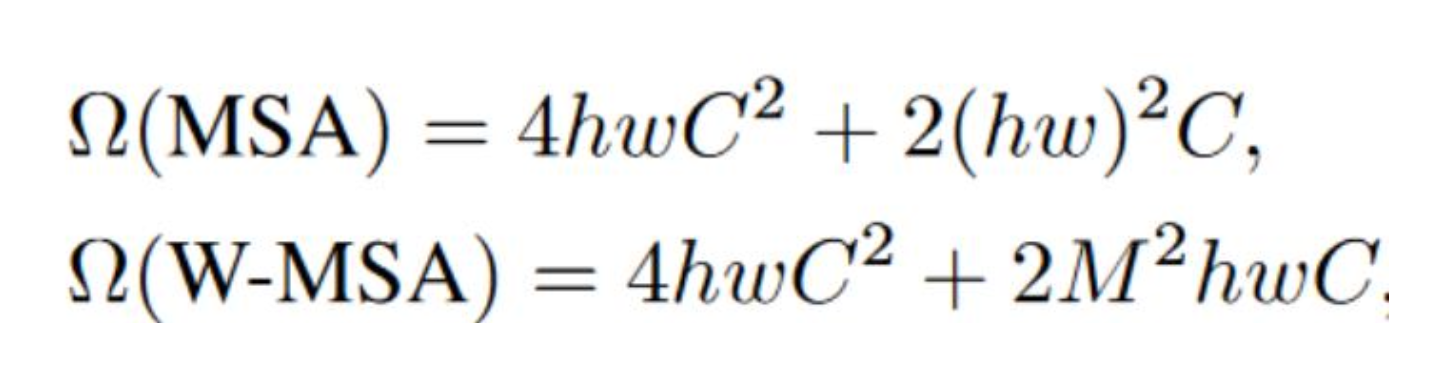
첫 번째 식이 ViT 의 Multi-head Self Attention 이고, 두 번째 식이 Swin Transformer 가 사용하는 Multi-head Self Attention 인데
두 식의 차이점은 hw (ViT) , MM (Swin) 밖에 없습니다. 이때 M 은 Window Size 입니다.
예를 들어 400x400 의 이미지를 처리한다고 생각해봅시다.
hw = 400x400
MM = 4x4
이므로, hw : MM = 10000 : 1 이 됩니다. 엄청난 차이입니다.
그래서 요약하자면, 1) 패치의 사이즈가 점점 커진다. 2) Window 범위 내에서만 Self-attention 을 수행한다.
이 두 가지를 Swin Transformer 의 차이점이라고 보시면 되겠습니다.
위 내용은 경희대학교 소프트웨어융합학과 황효석 교수님의 2023년 <심층신경망을 이용한 로봇 인지> 수업 내용을 요약한 것입니다.
'딥러닝' 카테고리의 다른 글
| 다양한 Knowledge Distillation 방법들 : 1. Response - based KD (1) | 2023.10.16 |
|---|---|
| Knowledge Distillation 개요 (0) | 2023.10.16 |
| 어텐션을 비전에 : ViT (Vision Transformer) (0) | 2023.10.02 |
| Transformer 완전 정복하기😎 (0) | 2023.09.25 |
| 왕초보를 위한 Self Attention (0) | 2023.09.21 |
Contents
소중한 공감 감사합니다