딥러닝
어텐션을 비전에 : ViT (Vision Transformer)
- -
Attention in Vision
Attention 을 CV 에 적용하기 위해서 다양한 방법들이 시도되어져 왔습니다.
이 그림은 "Stand - Alone Self-Attention in Vision Models" 라는 논문에 나오는 그림인데,
어떤 값을 낼 때 Convolution 을 하는 게 아니라, 가운데 있는 픽셀 값을 Query 로 날리고 Key 는 Fully connected로 학습해서 만들고, Value도 곱해서 만들어서 Self-attention 을 하기는 했습니다.
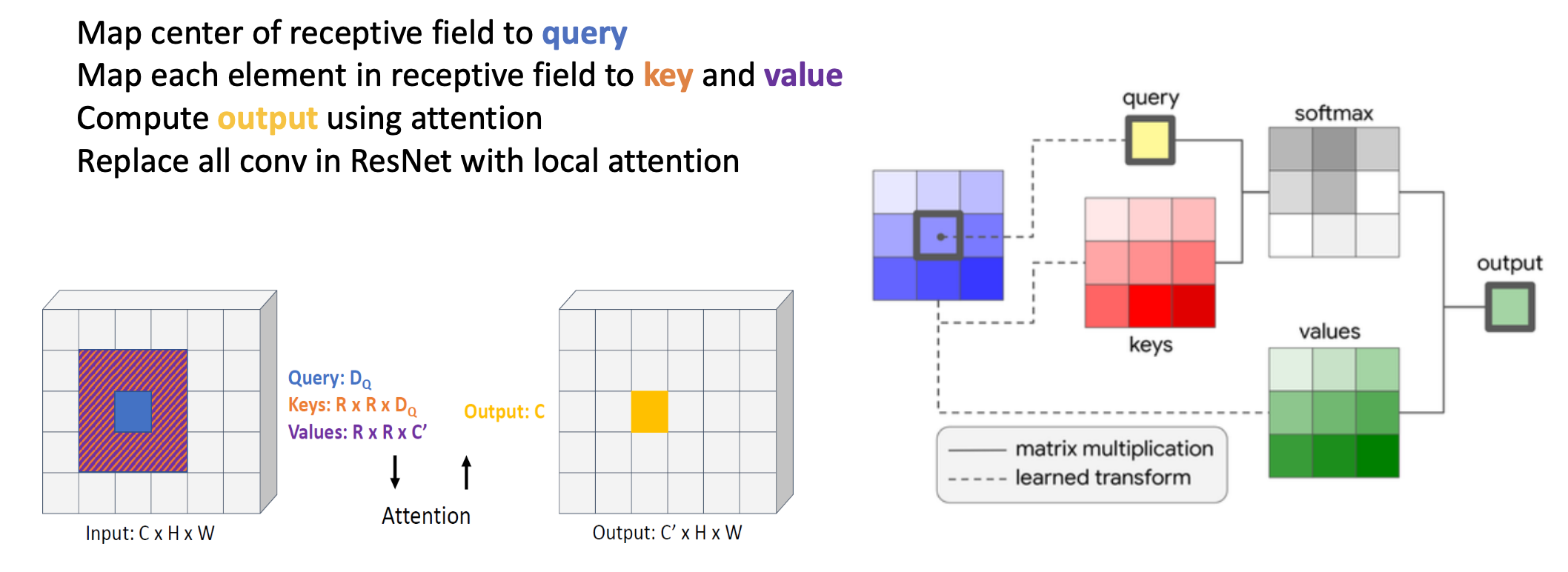
다만 이 구조도 CNN 의 Locality 를 극복하지는 못 했습니다.
그 다음에는 NLP의 word 대신 pixel 을 넣는 네트워크들이 제안되기는 했는데, 메모리 사용량이 너무 많다는 단점이 있었습니다. 원리상으로는 pixel 단위로 해도 되지만, 효율성이 떨어진다는 것입니다.
그래서 제안된 것이 patch 단위로 다루는 Vision Transformer 입니다.
patc 하나 하나를 NLP 에서 word 에 해당하는 것으로 간주하고 처리하게 됩니다.
Vision Transformer

Input Image
- Preprocessing : 224x224
- Patch size : 16x16 = 256
- Patch number : 14x14 = 196
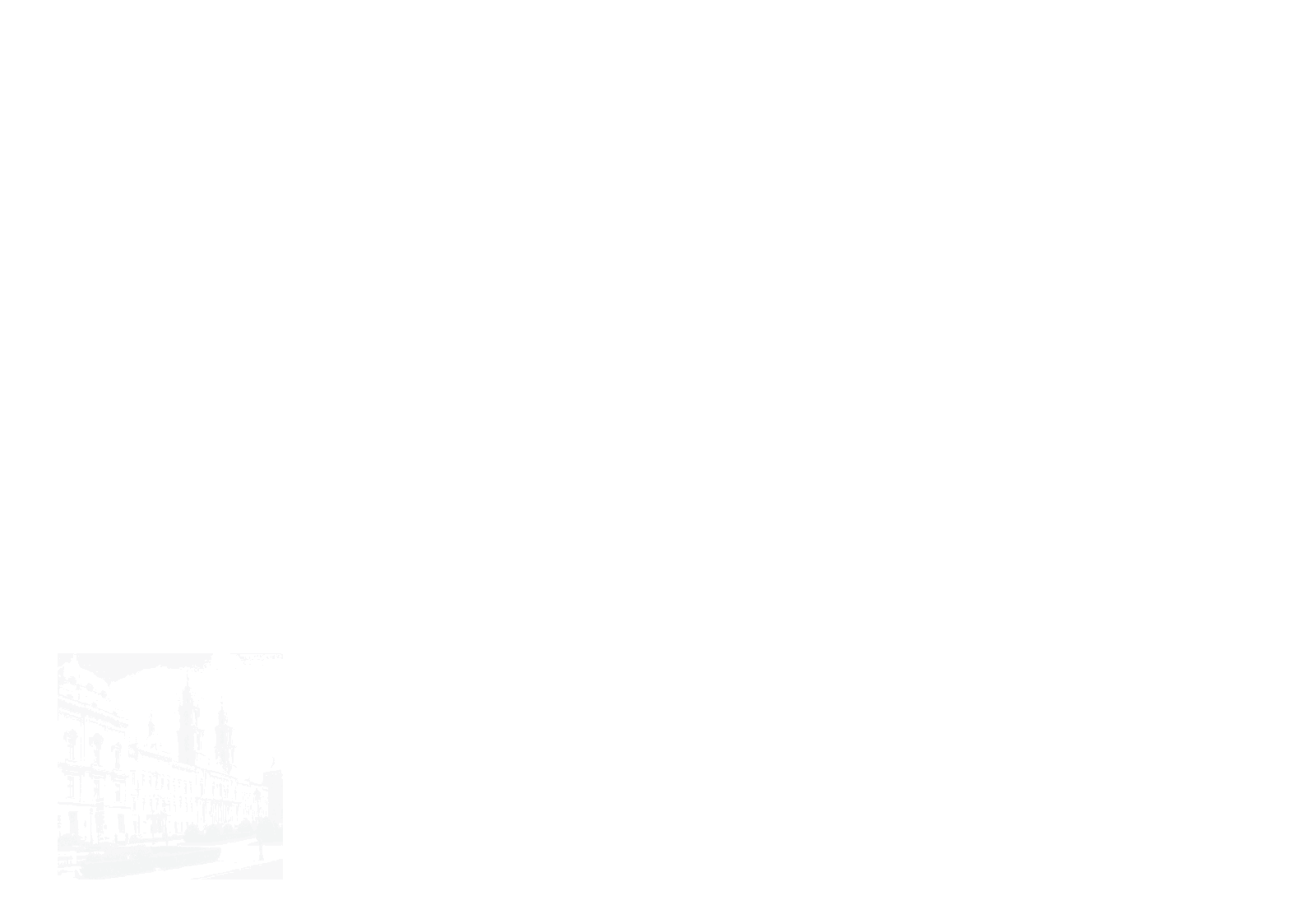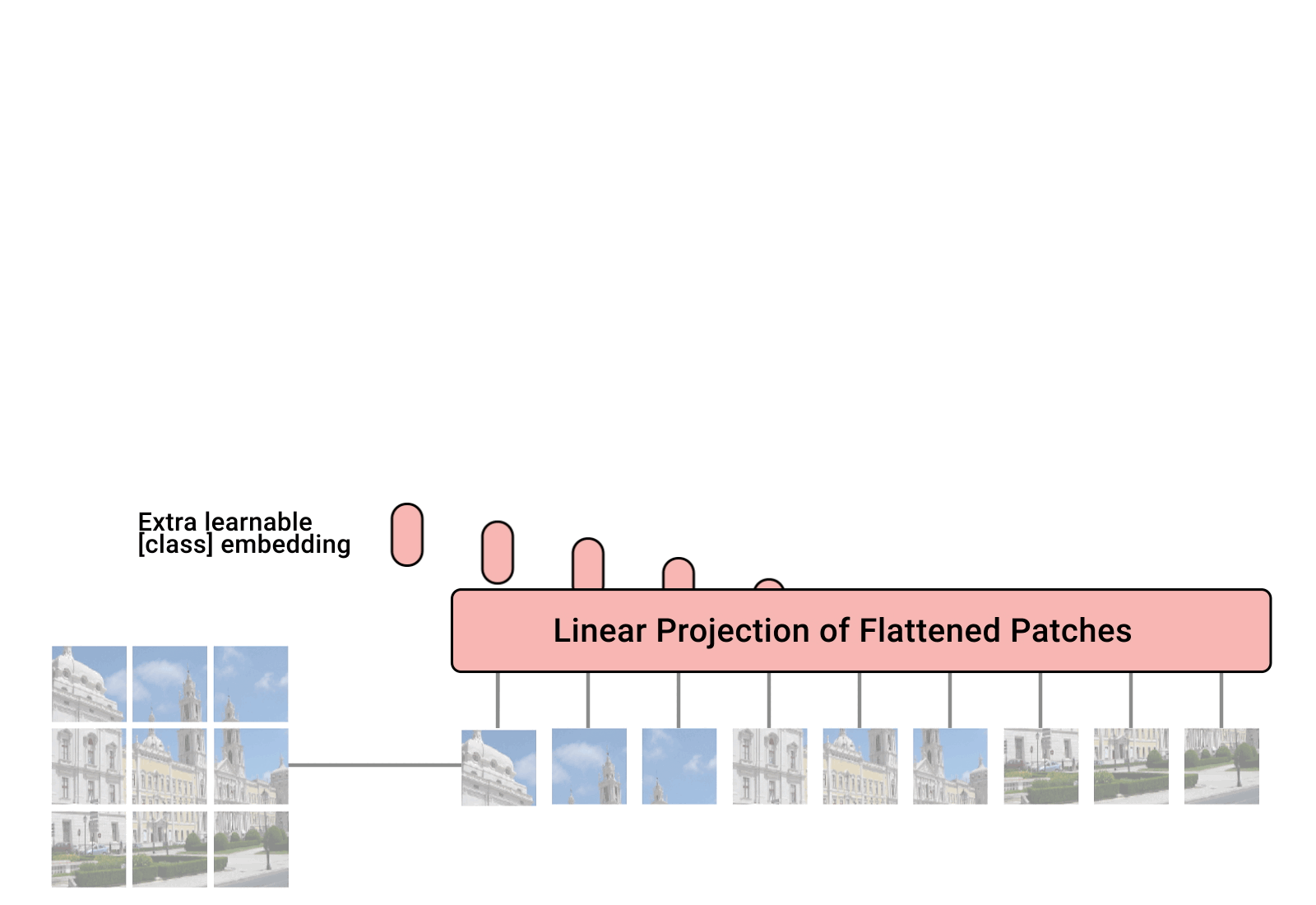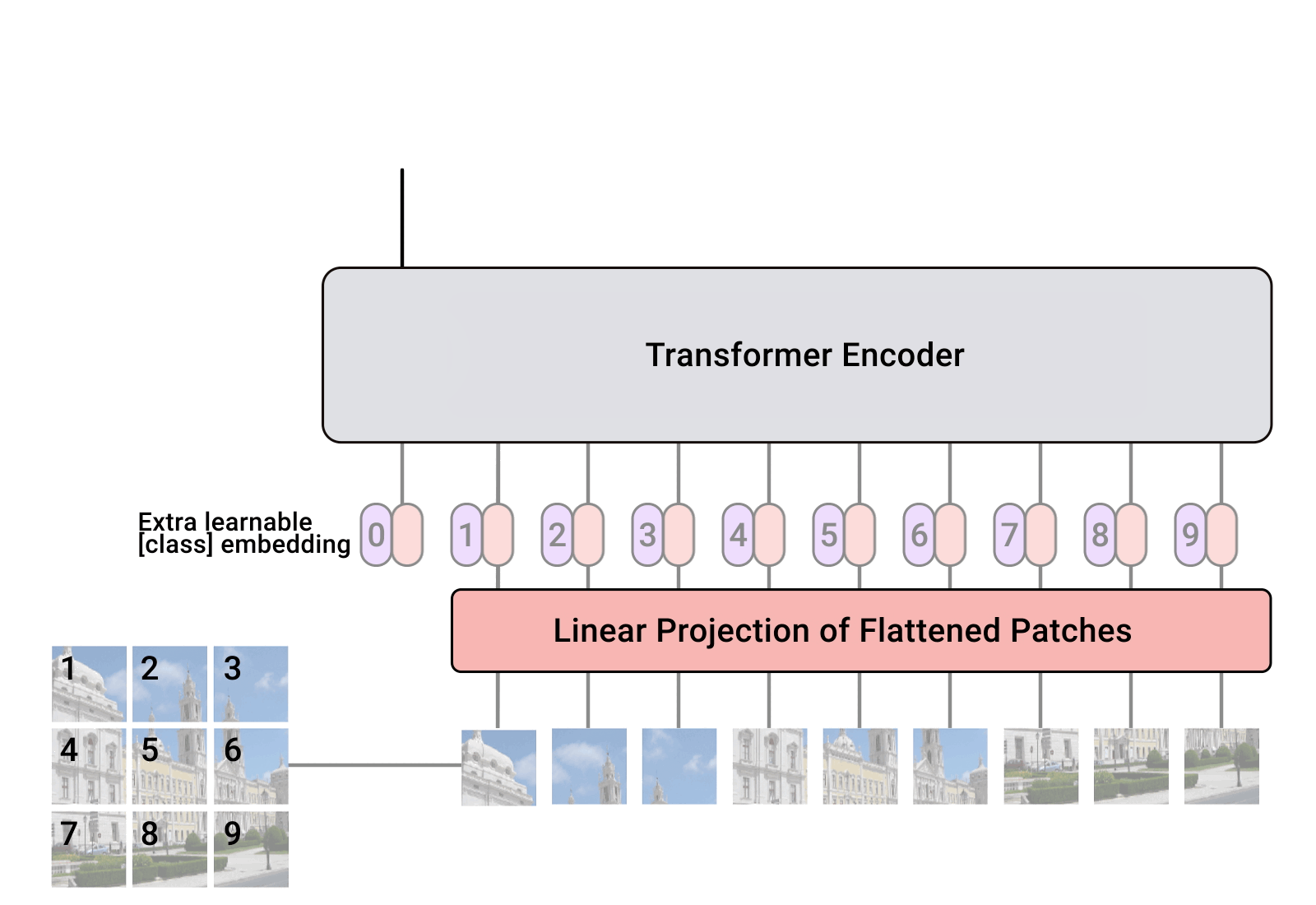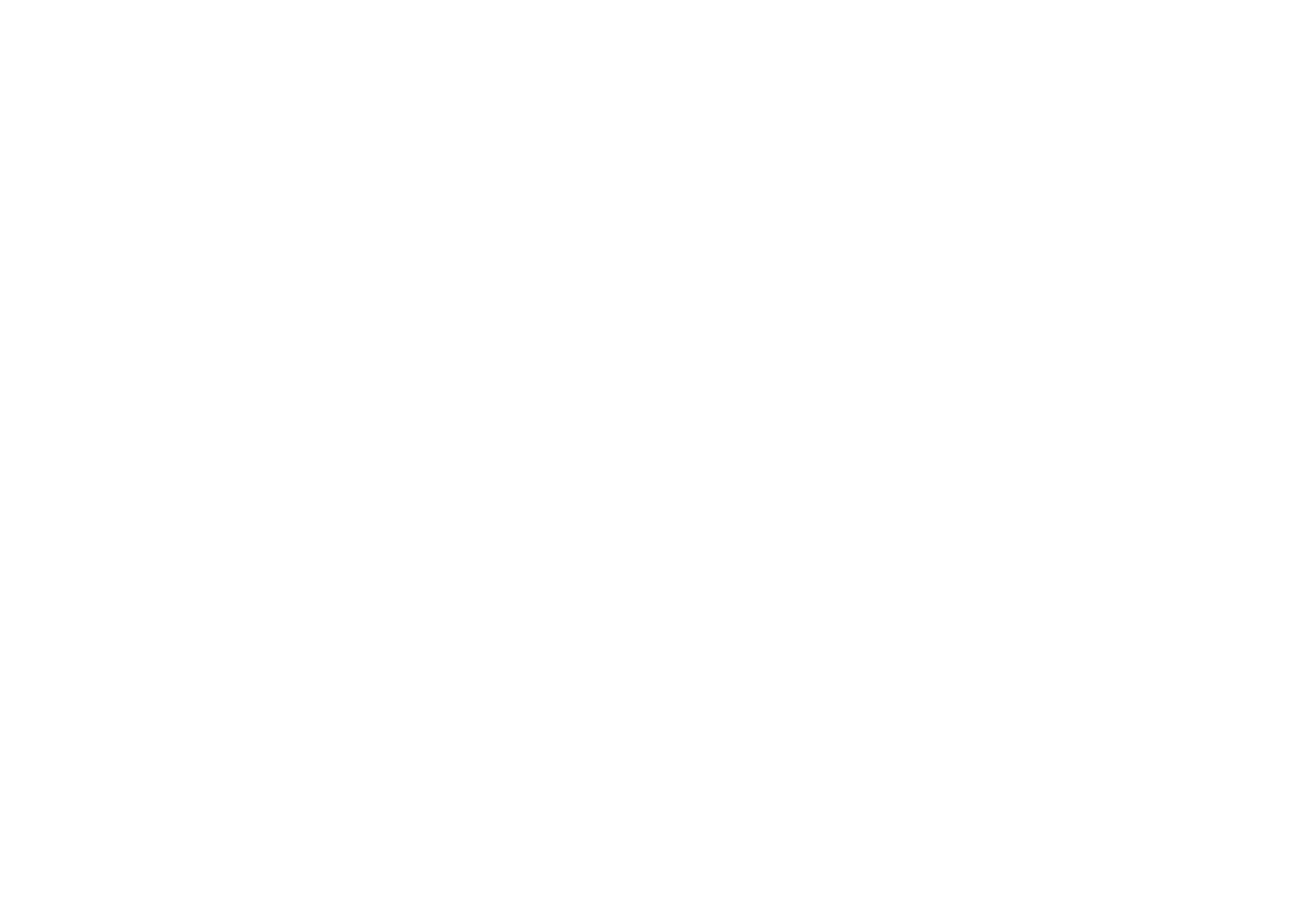
다음 이미지가 ViT 를 설명하는 전부입니다.
우선 이미지가 196 장으로 나눠져서, positional embedding 하고, transformer encoder 에 들어가게 된다는 것입니다.
Patches
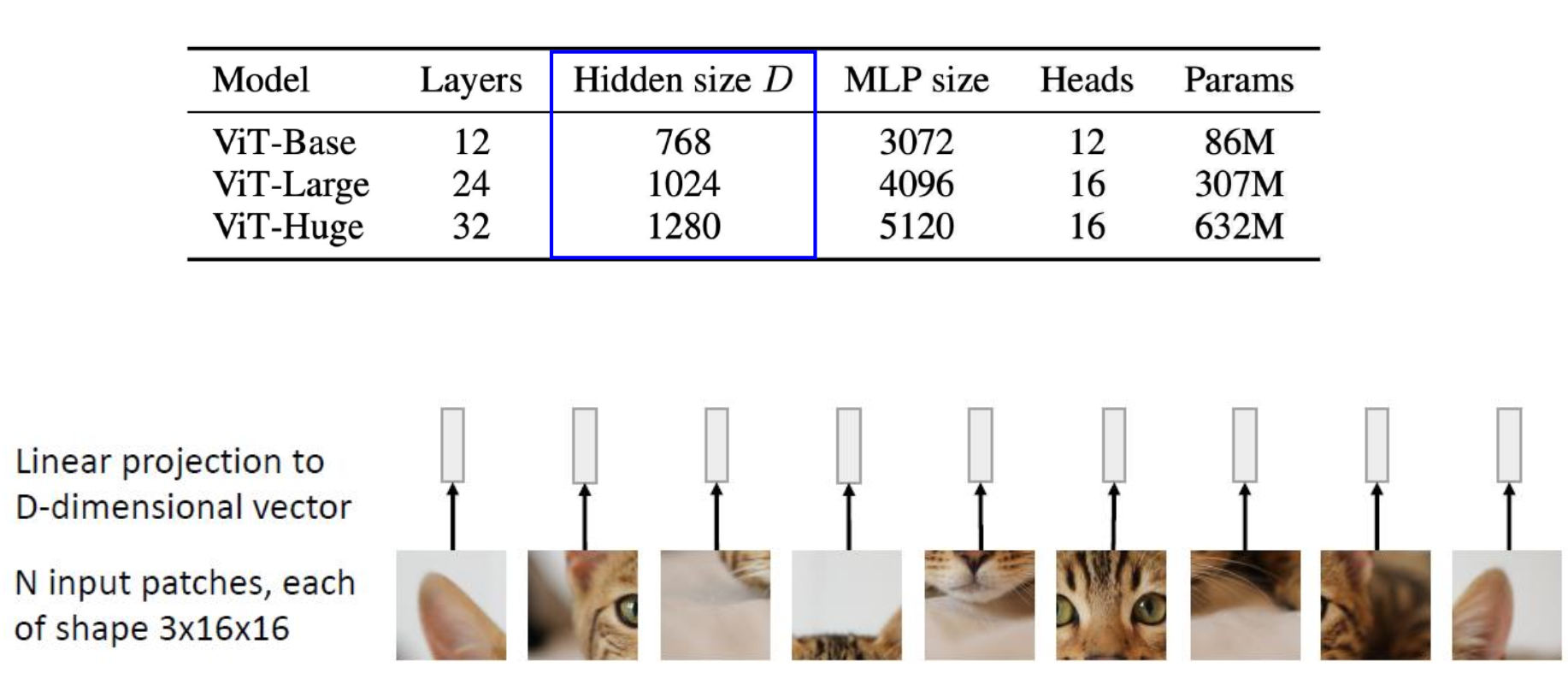
RGB 이미지이므로 하나의 패치는 3x16x16 = 768 개의 픽셀로 이루어져 있습니다.
그 다음에는 Linear Projection 을 수행합니다.
ViT 에서의 Linear Projection 은 입력 이미지를 고정된 크기의 패치들로 분할하고, 각 패치들을 1차원 벡터로 평탄화한 뒤 선형 변환을 수행해 해당 패치들을 임베딩 공간으로 투영하는 과정을 의미합니다.
Vision Transformer 에는 크게 3가지 모델이 있는데, 각각 Base, Large, Huge 입니다.
이들의 크기는 결국 architecture 의 크기 (파라미터의 갯수) 입니다. 여기서 Hidden Size 는 768 개를 몇 dimension 으로 embedding 할 것인지에 따라 결정됩니다.
- 1 patch : 16x16 pixels = 256 pixels, 256 x 3 channels = 768 pixels
- 1 image (224 px x 224 px) : 14 x 14 patches = 196 patches = N
- Linear projection to 1024 dimensions (ViT-Large)
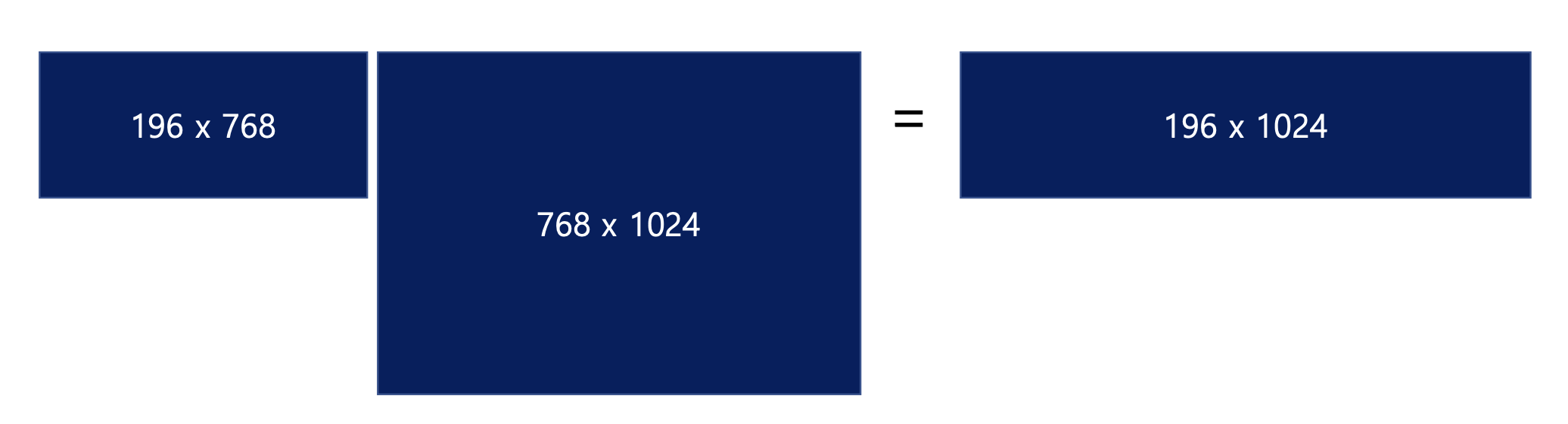
여기서 입력에 대해 곱해지는 weight 들은 global filter 의 역할을 합니다.
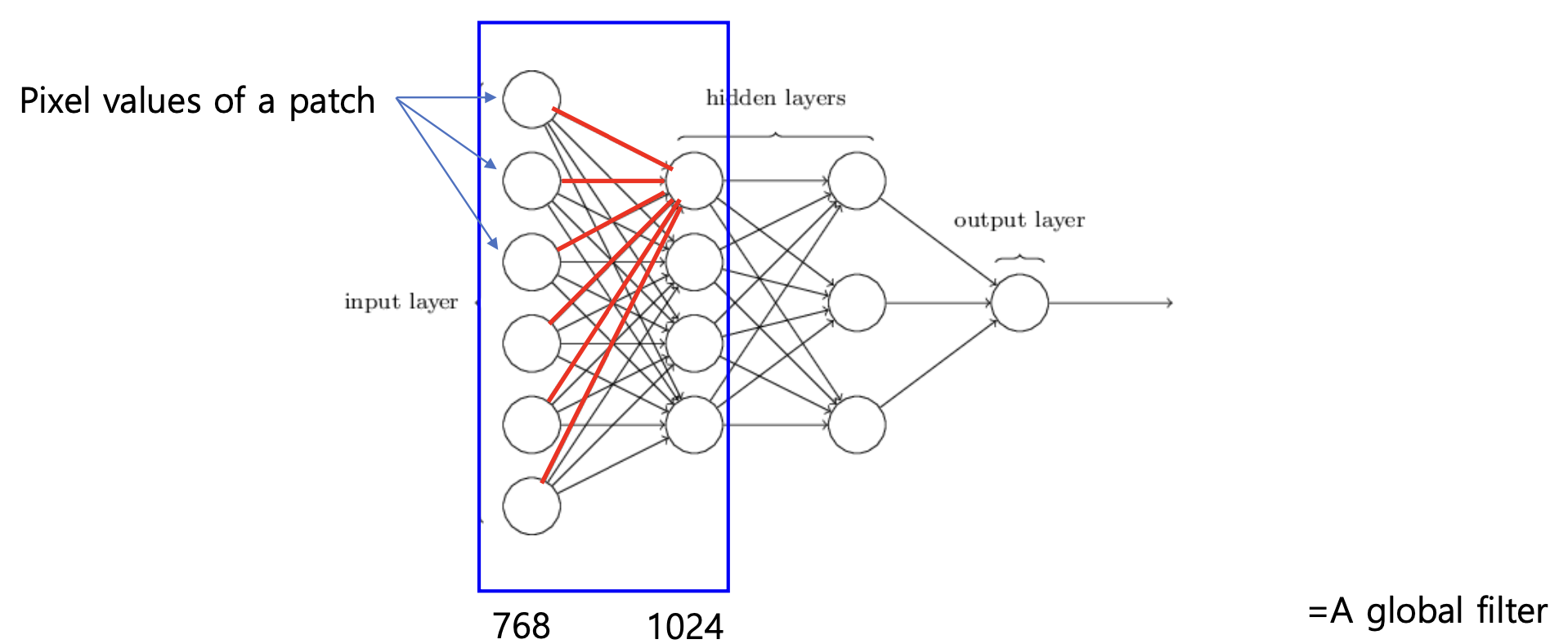
2D convolution 인데, convolution kernel 이 이미지의 크기와 똑같은 것과 같습니다.
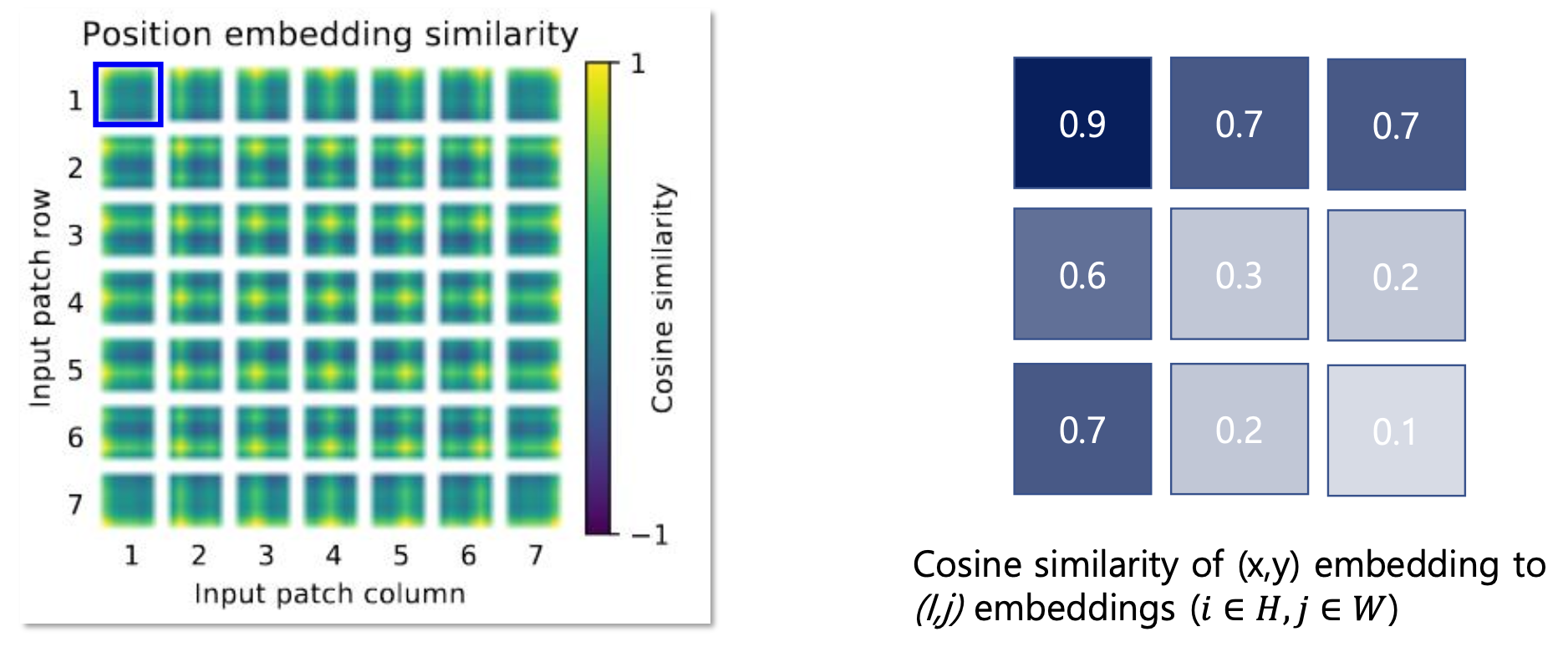
Positional Embeddings
그러면 이제 우리들은 patch 를 768 의 길이를 가진 vector 로 projection 했습니다. 이들은 하나 하나가 필터들에 대한 응답값입니다. 이후에는 transformer 와 마찬가지로 이들을 positional embedding 을 합니다.
ViT 에서는 positional embedding 도 학습을 했습니다. (이전 Attention 에서는 sine, cosine 을 이용해서 했었습니다.)
Transformer encoders with token
NLP 에서 transformer 는 모든 단어마다 다음에 올 단어를 예측하는 식으로 마지막에 계산이 이루어졌기 때문에 내가 예측하는 위치가 계속 바뀌었었습니다. 하지만 vision transformer 는 196 + 1 <- 이런 식으로 패치를 하나 더 넣어줍니다.
총 197 개의 vector 가 transformer 를 통과하게 되는 것이죠.
이 197 개의 vector 들이 네트워크를 통과하며 값을 공유하게 되고, 마지막에 나온 1개의 벡터를 fully connected layer 로 만들어서 클래스의 확률값으로 계산하게 됩니다.
196 개를 모두 사용해서 최종 결과를 내는 것이 아니라, 확률값은 1개의 벡터에서만 취하겠다는 것입니다. 이를 CLS 토큰 (Classification 토큰) 이라고 합니다.
꼭 이렇게 해야 하는 것은 아닙니다. 어떤 구조들은 결과를 평균내서 사용하기도 하니까요. 어쨌든 ViT 는 하나의 벡터에서 결과를 취득하는 방식으로 최종 결과를 냈습니다.
위 내용은 경희대학교 소프트웨어융합학과 황효석 교수님의 2023년 <심층신경망을 이용한 로봇 인지> 수업 내용을 요약한 것입니다.
'딥러닝' 카테고리의 다른 글
| Knowledge Distillation 개요 (0) | 2023.10.16 |
|---|---|
| 큰 이미지에서 동작하는 ViT : Swin Transformer (0) | 2023.10.04 |
| Transformer 완전 정복하기😎 (0) | 2023.09.25 |
| 왕초보를 위한 Self Attention (0) | 2023.09.21 |
| 어디에 주목할 것인가 ? : Spatial Attention - STN (Spatial Transformer Network) (0) | 2023.09.16 |
Contents
소중한 공감 감사합니다