딥러닝
다양한 Knowledge Distillation 방법들 : 1. Response - based KD
- -
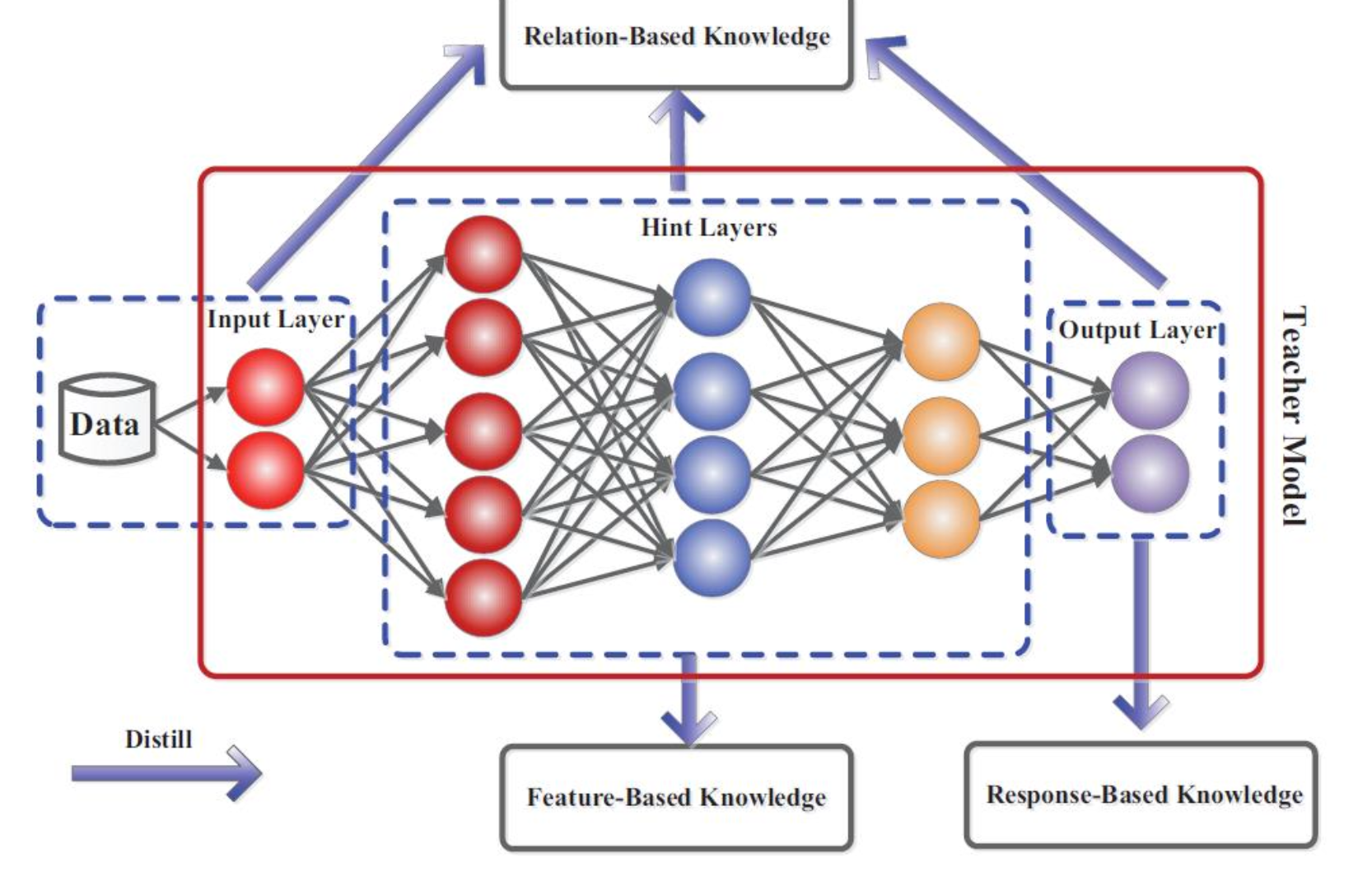
무엇을 배우는가 ? 의 관점에서 KD 는 크게 3가지로 분류할 수 있습니다.
- Response-Based : 결과값을 따라가는 것
- Feature-Based : 중간에 나오는 값들 (과정) 도 다 따라가는 것
- Relation-Based : 단편적인 값들의 비교가 아닌, 중간 중간의 값들이 어떤 프로세스에 의해 나오는지 (Flow) 흐름도 따라가는 것
What to match ?
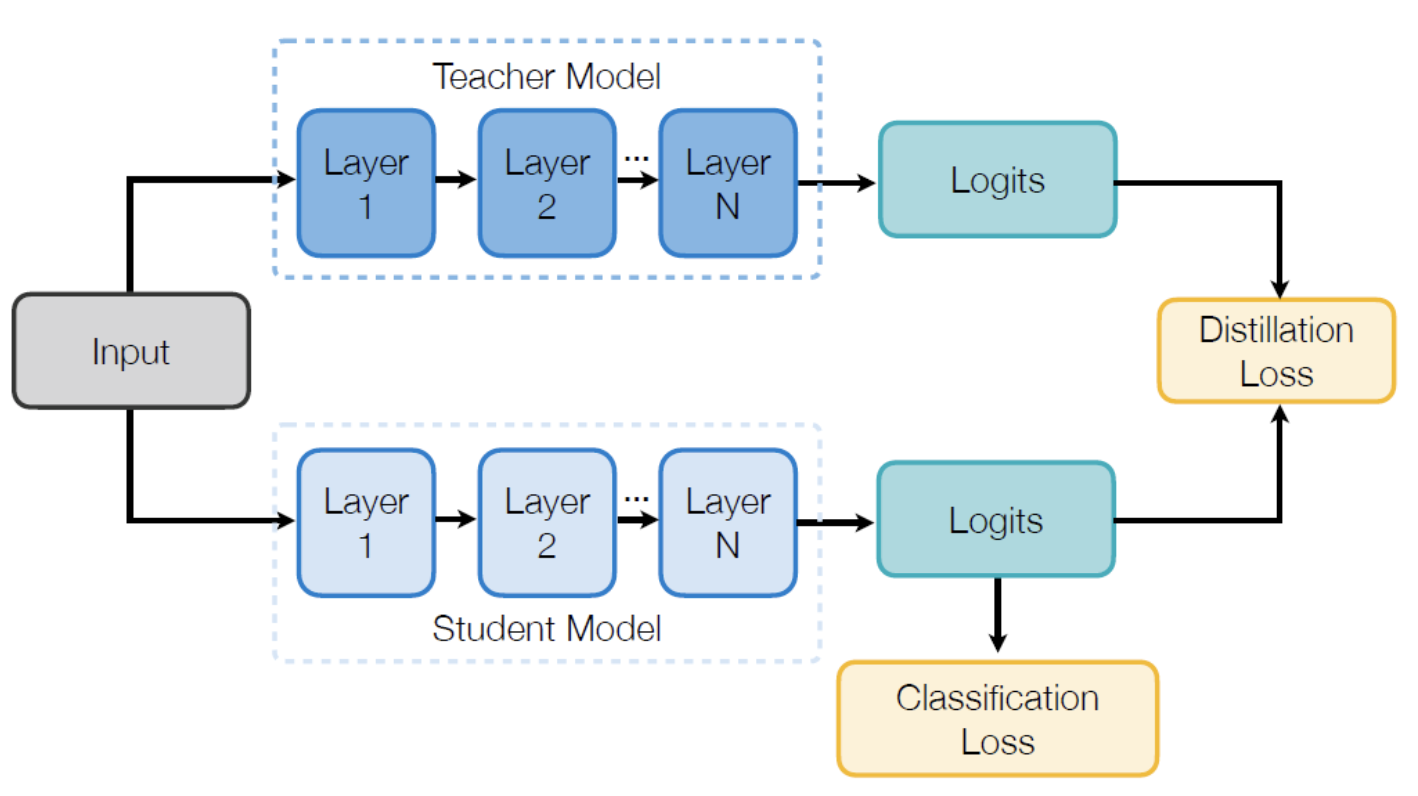
Output Logits
Output logit 을 따라가는 것은 직관적이고 이해하기 쉽습니다. 하지만 이는 Supervised Learning 에서밖에 사용할 수 없습니다. 답이 있어야 하니까요.
Intermediate Features
중간 feature 값으로부터 학습을 하는 것입니다.
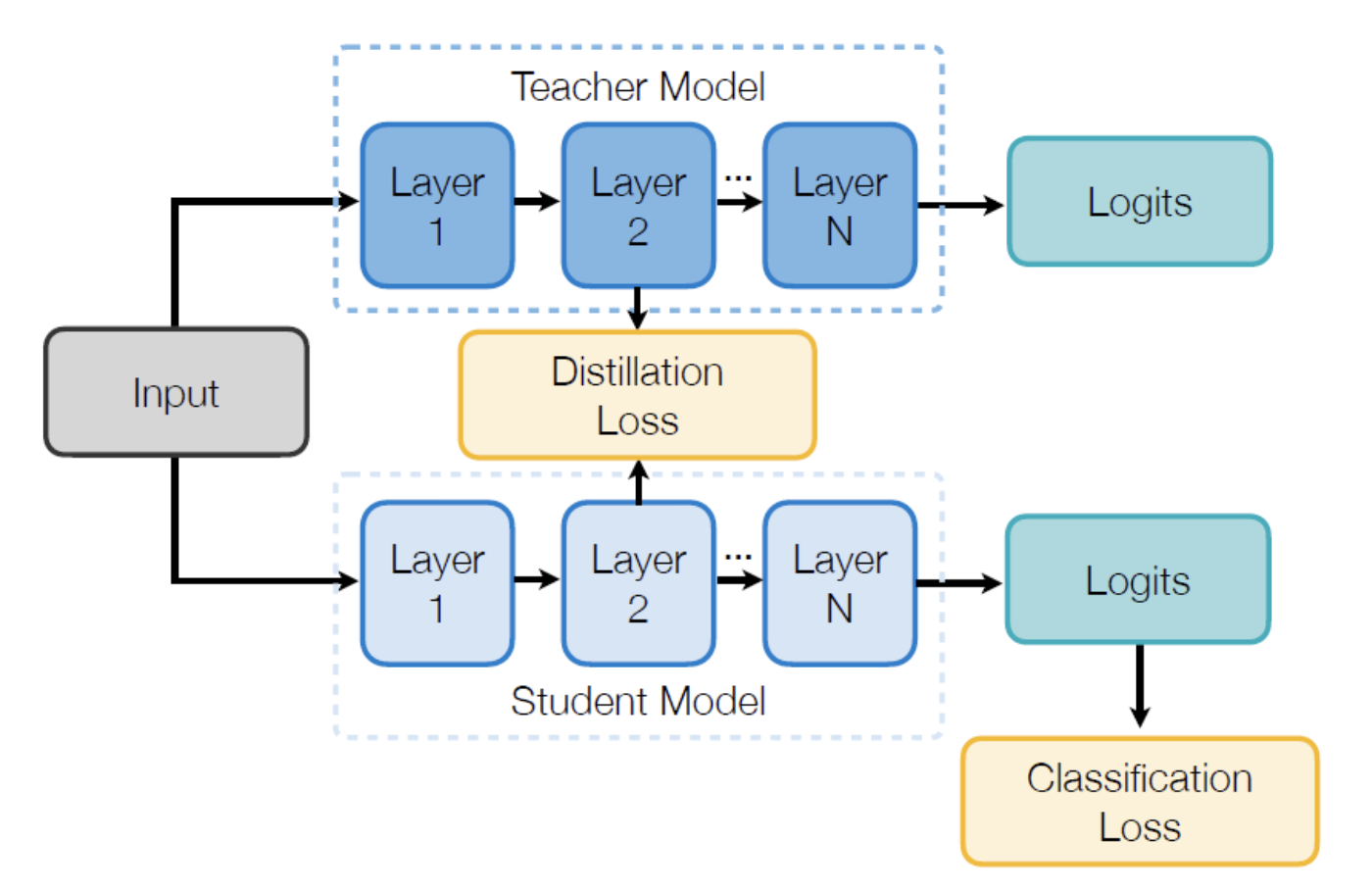
하지만 이런 Feature 를 matching 할 때는 고려해야 할 점이 훨씬 많아집니다. 우선, Teacher 와 Student 는 그 모델의 모양이 다를 가능성이 매우 높습니다. Teacher 는 거대하고 복잡하고, Student 는 작고 간단하니까요.
그래서 중간 중간 Feature 값을 비교하려고 해도, Depth 가 다를 수도 있고 크기가 다를 수도 있습니다. 그래서 1:1 매칭이 되지 않을 수 있습니다.
그래서 Feature Distillation 을 하기 위해서는 고민해 보아야 할 것들이 많이 있습니다.
- 과연 Feature 가 무엇인가 ?
- 어떻게 모양을 맞춰줄 것인가 ?
- Distance 는 어떻게 정의할 것인가 ?
Response - based KD (Logit - based KD)
Added Class-distance loss : Maximize margins between classes
Kim, Seung Wook, and Hyo-Eun Kim. "Transferring knowledge to smaller network with class-distance loss." (2017).
이 논문에서는 클래스에 대한 logit 들을 평균을 냅니다. 그러면 클래스들에 대한 평균 벡터가 생성됩니다.
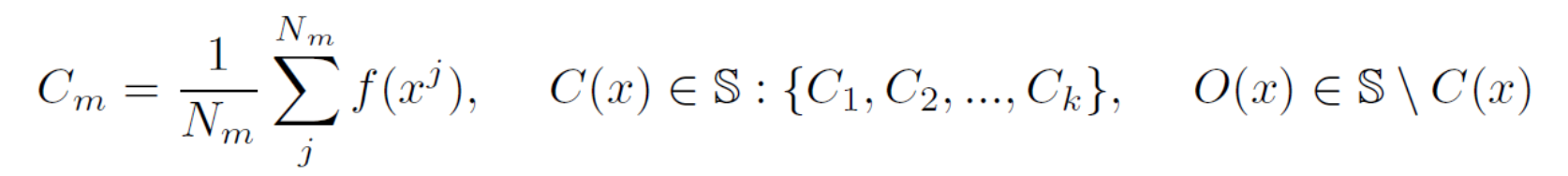
예를 들어 10개의 평균 벡터가 있다고 할 때, 이 평균 벡터들의 집합을 S 라고 하고, O(x) 는 전체 집합에서 x 클래스를 제외한 나머지 집합이라고 정의합니다.
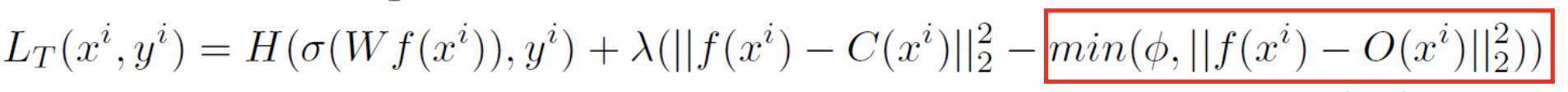
이 Loss function 이 의미하는 것은 두 가지입니다.
- Student 의 x 에 대한 logit 평균은 Teacher 의 x에 대한 logit 평균의 차이는 작아야 한다.
- Student 의 x 에 대한 logit 평균과 Teacher 의 x 를 제외한 logit 평균의 차이는 커야 한다.
Adaptive Regularization of Labels
Ding, Qianggang, et al. "Adaptive regularization of labels." arXiv preprint arXiv:1908.05474 (2019).
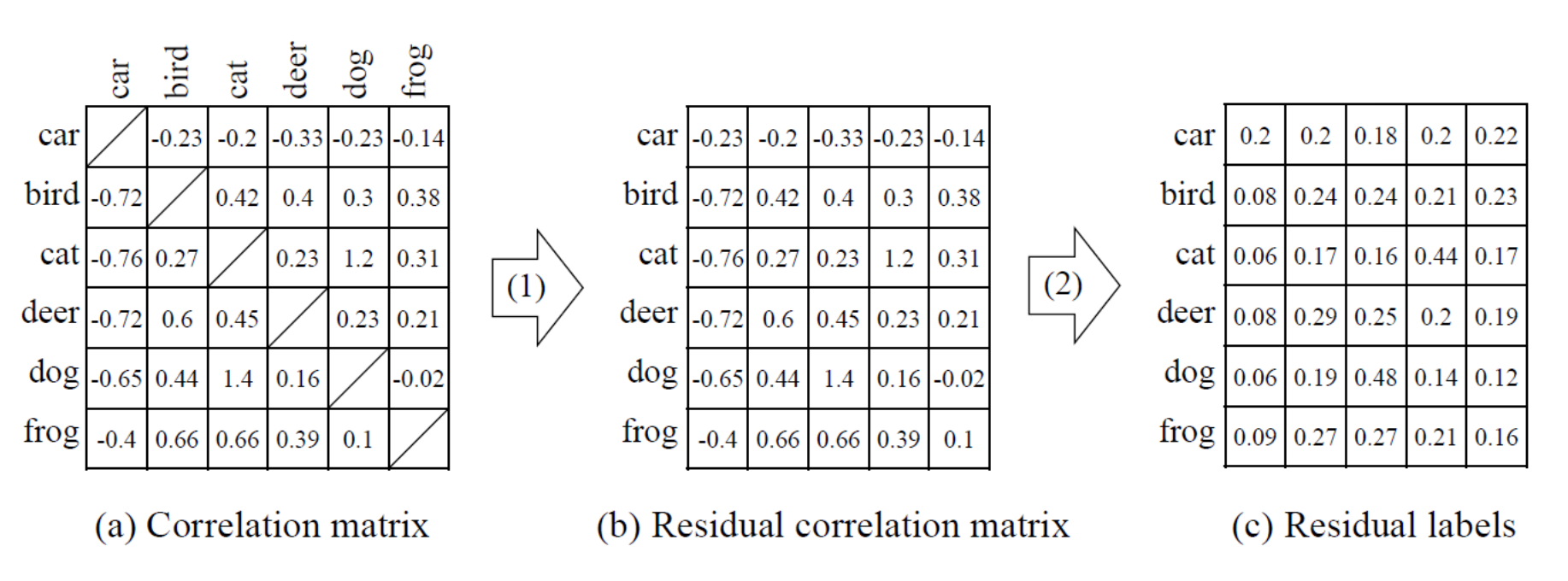
이 논문에서는 Correlation matrix 를 만들어서 Correlation matrix 와 유사하도록 자가 학습을 하는 방식입니다.
따라서 Teacher의 Soft label 만 학습을 하는 것이 아니라, 이런 Soft label 과 유사한 Correlation 값들을 계속 쌓아서 하나의 전체적인 값들을 만들어 놓고 Student 가 이들과 유사해지도록 학습하는 것입니다.
그러면 결국 이 Correlation matrix 는 특정 클래스와 다른 클래스들이 얼마나 유사한지를 나타내게 됩니다.
Multi - level Logit Distillation
Jin, Ying, Jiaqi Wang, and Dahua Lin. "Multi-Level Logit Distillation." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023.
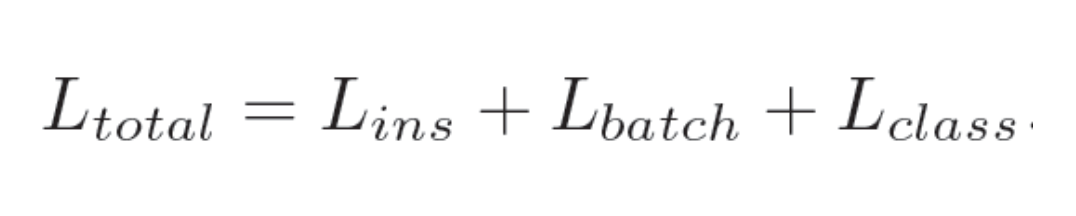
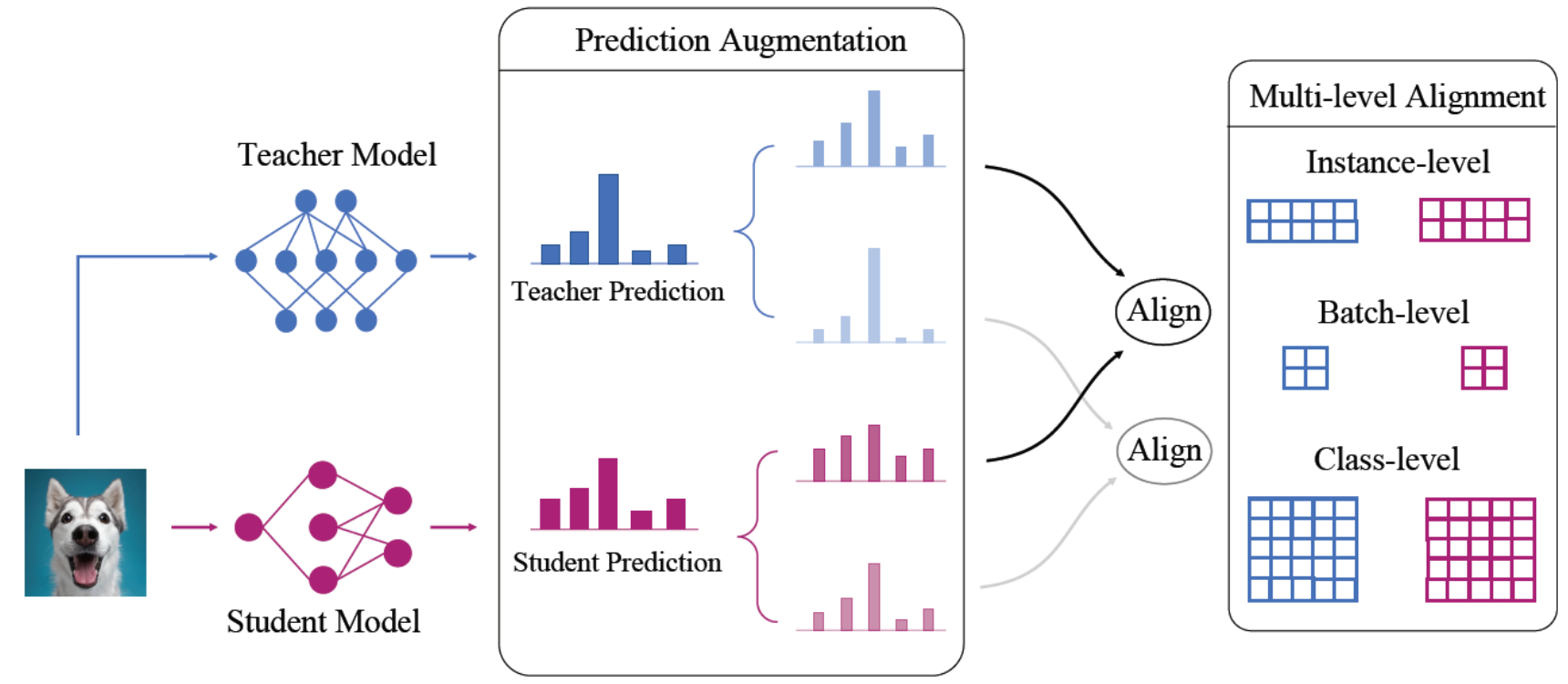
이 논문은, 어떤 logit 이 나오게 되면 그냥 Teacher - Student 로 1:1 매칭하는 것이 아니라 좀 더 다양한 카테고리로 묶어서 해 보는 방식을 제안했습니다.
- Instance : instance prediction
- Batch : input correlation
- Class : category correlation
Mutual Information
이 분야를 공부하면서 자주 마주치는 Mutual Information 이라는 용어가 있습니다. 말 그대로 "상호 정보" 입니다.

확률이 낮을 수록 정보량이 큽니다. 그리고 엔트로피는 정보량의 기댓값입니다.
Joint Entropy
The joint entropy represents the amount of information needed on average to specify the value of two discrete random variables
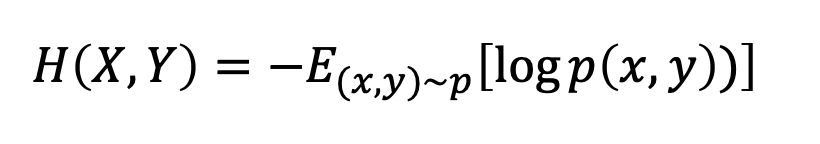
Conditional Entropy
The conditional entropy indicates how much extra information you still need to supply on average to communicate Y given that the other party knows X
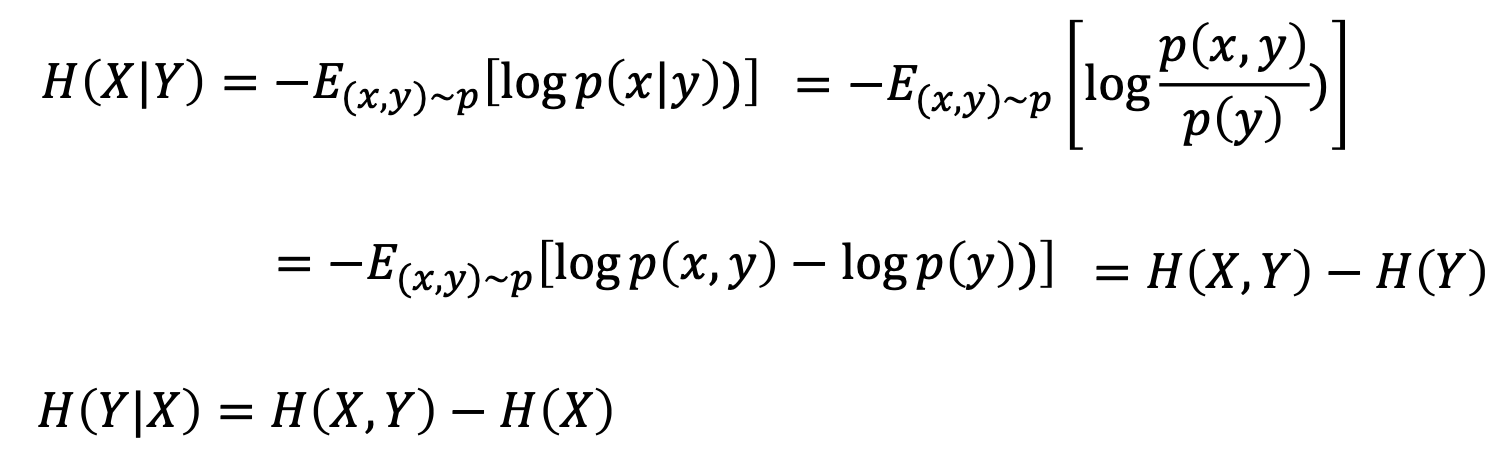
Conditional entropy 는 "joint probability 에 대한 entropy" 라고 볼 수 있습니다.

위 내용은 경희대학교 소프트웨어융합학과 황효석 교수님의 2023년 <심층신경망을 이용한 로봇 인지> 수업 내용을 요약한 것입니다.
'딥러닝' 카테고리의 다른 글
| Self - Supervised Learning : Contrastive Learning (0) | 2023.11.09 |
|---|---|
| Self - Supervised Learning : Pretext Task (0) | 2023.11.09 |
| Knowledge Distillation 개요 (0) | 2023.10.16 |
| 큰 이미지에서 동작하는 ViT : Swin Transformer (0) | 2023.10.04 |
| 어텐션을 비전에 : ViT (Vision Transformer) (0) | 2023.10.02 |
Contents
소중한 공감 감사합니다