딥러닝
Contrastive Learning : Moco (Momentum Contrast)
- -
Contrastive Learning 을 하는 이유는 Postive Pair 는 가깝게, Negative Pair 는 멀게 하기 위함입니다.
여기서 가장 흔히 사용되는 Loss 는 InfoNCE 라는 loss 입니다. 다만 이후 Clustering 을 할 때 있어서 문제가 발생합니다.
InfoNCE 로 인코더를 학습하고 나면 x와 x' 의 위치는 Embedding space 상에서 가까워 지게 됩니다. 그런데 과연 가까워 지는 쪽으로 업데이트를 하는 게 옳을까요 ?
가까워지는 방향에 Negative Pair 들이 있다면 어떻게 될까요 ? Negative Pair 들이 없는 방향으로 옮겨가야 하지 않을까요 ?

즉, Negative 랑은 멀게, Positive 랑은 가깝게 하려면 momentum 을 고려해야 합니다.
Momentum Contrast (MoCo)
He, Kaiming, et al. "Momentum contrast for unsupervised visual representation learning.“, CVPR, 2020
- Key issue : the number of negatives is very crucial in contrastive learning
- 이 문제를 해결했던 기존 방법 : Memory Bank
Query 와 Key
MoCo 는 각 이미지에 대해서 두 가지 view 를 생성합니다.
- Query 는 현재 모델로부터 생성되며 Key 는 고정된 Queue 에서 가져옵니다.
- MoCo 는 두 개의 인코더를 사용하는데, Key 인코더는 Query 인코더의 가중치를 모멘텀 업데이트 방식을 사용하여 갱신합니다.
Memory Bank
메모리 뱅크는 학습 과정에
Negative sample 들이 많으면 좋지만 그렇게 되면 필요한 메모리가 너무 많다는 단점이 있습니다. 그래서 Memory bank 라는 개념이 도입되었습니다.
Memory bank 를 이용하면 뽑은 Feature 들을 memory bank 에 집어넣고 그 feature 를 바로 꺼내 쓸 수 있다는 장점이 있습니다. 다만, Memory bank 에도 문제점이 있습니다.
Feature 자체를 가지고 있기 때문에, 인코더가 업데이트되면 쿼리와 키가 사실상 달라진다는 것입니다.
그래서 얘네들을 바로 업데이트 하는 게 아니라 모멘텀을 이용해서 조금씩 업데이트하는 방법이 제안되었습니다.
그래서 이 방법에서는 우선 Dictionary Queue 를 만듭니다. 이후 Query 를 할 요소를 Augmentation 해서 인코더에 넣습니다. 그러면 두 개가 인코딩 되어서 Feature 들이 나옵니다.
나온 Feature 들에 One-hot 을 붙입니다.
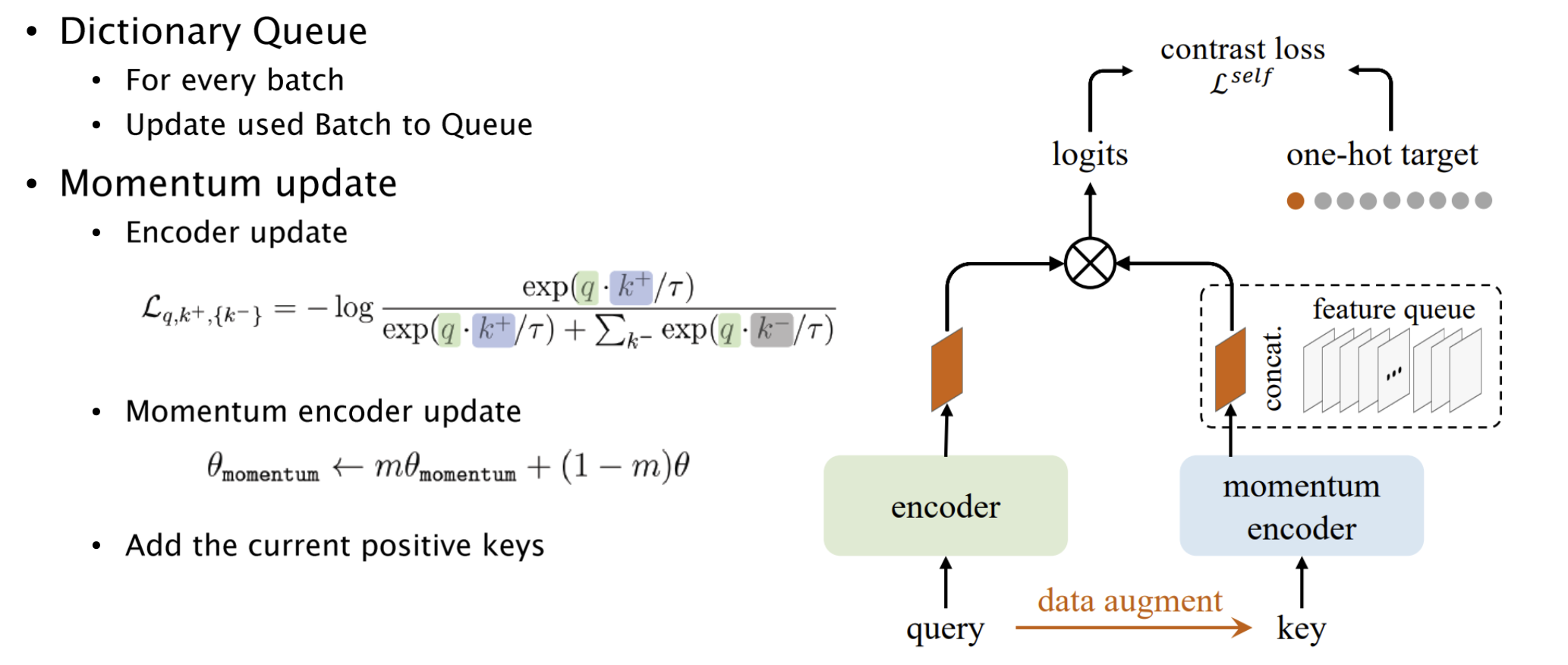
이후 학습을 진행하고, momentum 을 반영해서 update 를 합니다.
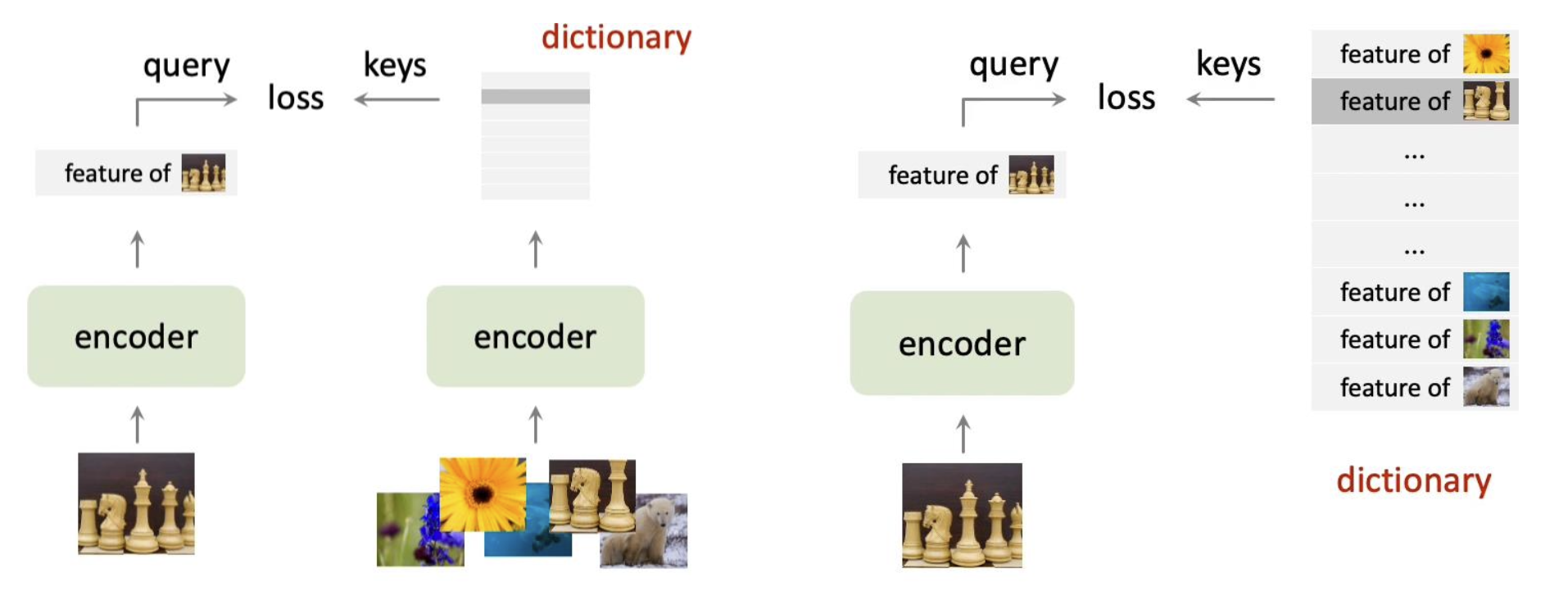
end-to-end 방법과 비교를 하면 end-to-end 방법은 모든 negative 를 encoding 해서 계산을 하는 반면에 momentum 은 내가 지금 하는 거만 올려서 positive 로, 나머지는 negative 로 계산합니다.
강화학습을 공부할 때는 결국 "업데이트를 어떻게 할 것인지" 가 가장 중요한 문제인데, 여기서 비슷합니다.
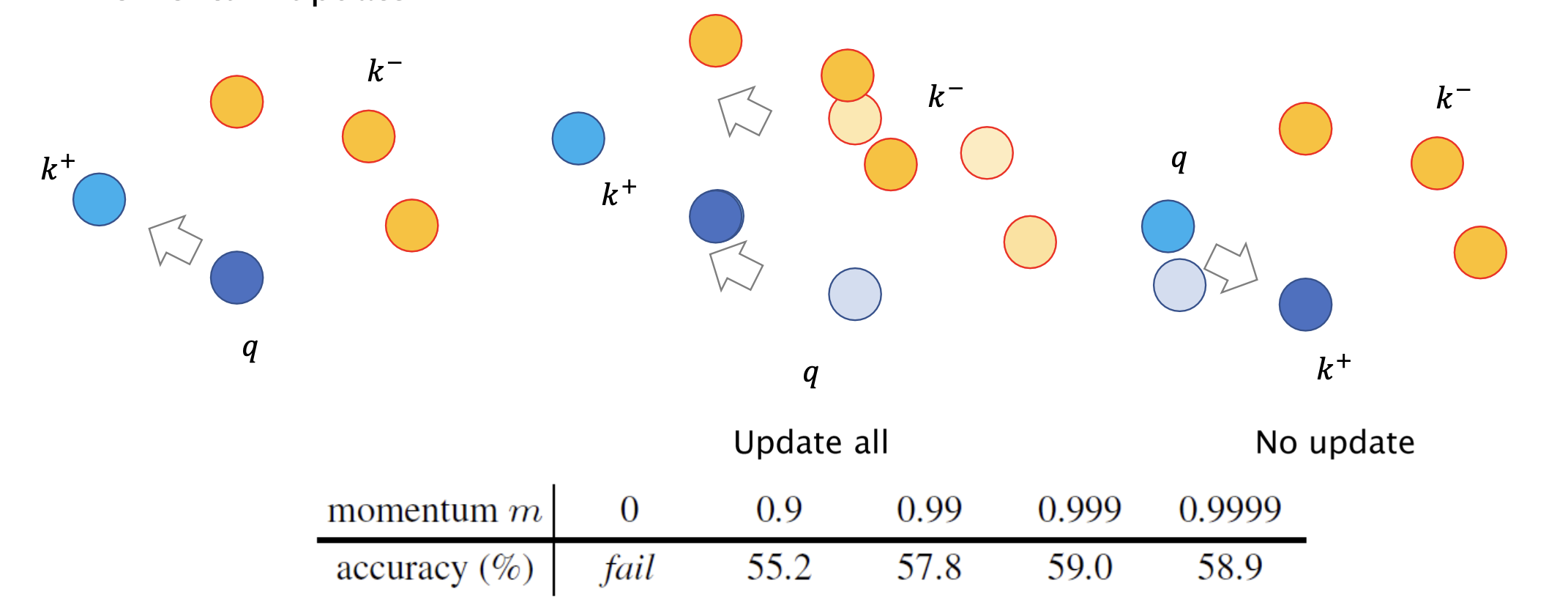
만약 k 와 q 가 가까워지도록 인코더를 업데이트하면 둘은 가까워지지만 나머지 애들도 다 가까워지게 됩니다. 그때그때 인코더 업데이트 값을 모든 샘플에 반영하는 게 학습에 도움이 안 됩니다.
그럼 Dictionary 처럼, 나머지 애들은 머물러 있으라고 하고 필요한 애들만 가까워지라고 하면 또 달라진 인코더는 전체 샘플의 위치를 모르게 된다는 단점이 있습니다.
그래서 원래 있는 negative sample 들의 feature 들의 변화를 어떻게 조절할 것인지가 중요한 문제입니다.
따라서 이 논문의 저자들은, 현재의 인코더 값을 매번 업데이트 해 주긴 하지만 매우 천천히 움직이도록 하였습니다.
저 표는 momentum 만큼 원래 있는 값을 쓰고, 새로운 값은 (1-momentum) 만큼만 반영해서 업데이트 할 때의 결과를 의미합니다.
위 내용은 경희대학교 소프트웨어융합학과 황효석 교수님의 2023년 <심층신경망을 이용한 로봇 인지> 수업 내용을 요약한 것입니다.
Contents
소중한 공감 감사합니다