딥러닝
왕초보를 위한 Self Attention
- -
Self Attention 까지 가기 위해서는 거쳐야 할 관문들이 조금 있습니다. Self Attention 이 나오게 된 배경, 그리고 이 많은 연구들 사이에서 Self Attention 이 어떤 위치에 있는지까지 알기 위해서, 먼저 Image Denoising 의 역사를 살펴볼 필요가 있습니다.
Image Denoising

실제와 다른 신호가 노이즈입니다. 이런 노이즈를 제거하기 위해, 예전에 사용하던 방법은 필터를 적용하는 것이었습니다. Box Filter, Gaussian Filter, Median Filter 등을 사용하는 이런 필터들의 공통점은 한 가지 가정을 따릅니다. 그것은 바로 "포인트의 값은 이웃들과 유사할 것이다" 라는 가정입니다. 다만 이런 가정은, 하늘이나 벽 처럼 Homogeneous 한 환경에서는 성립하지만 Edge 같은 환경에서는 성립하지 않습니다.
따라서 이런 단점을 극복하기 위해, Bilateral Filter 가 고안되어 많이 사용되어져 왔습니다.

Bilateral Filter 의 식은 다음과 같은데, 이는 거리에 따른 Gaussian 과 Intensity 에 따른 Gaussian 을 곱해서 최종 결과를 냅니다. 이렇게 되면 엣지는 잘 보존하고, 나머지 부분에서는 노이즈가 제거된 이미지를 얻을 수 있습니다.
이 모든 것들은 Local Filter 입니다. 주변에 있는 값들만 참고해서 결과를 내기 때문입니다.
Non-local means filter
반면 주변에 있지 않은 값들도 참고해서 결과를 내는 필터들도 있습니다. 이를 Non-local filter 라고 합니다.
- Bilateral Filter : Similar Intensity 를 가진 주변의 이웃들을 평균을 낸다.
- Non - Local mean Filter : 이미지 전체에서 비슷한 패턴을 찾아서 해당 픽셀의 값을 필터링하는 데 사용
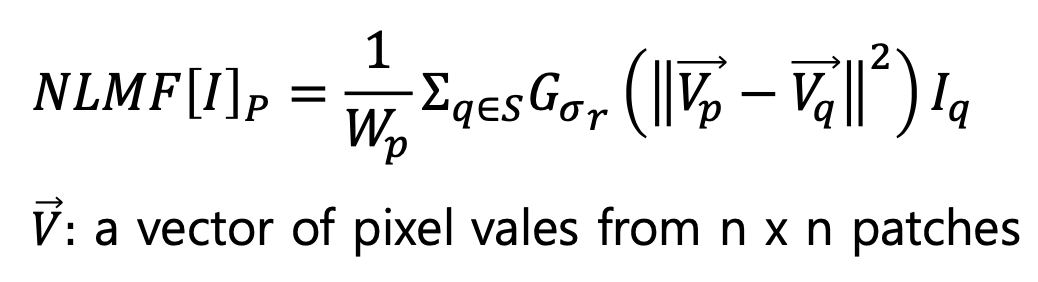

기하학적으로만 보자면 노란색 q 기준으로, 하얀색 q 보다 노란색 q 가 더 가깝지만 유사도는 하얀색 q 가 더 높다고 할 수 있습니다.

이런 필터들을 DNN 과 연관지어서 생각해보면, Local Filter들은 CNN 과 유사한 방식을 사용한다고 할 수 있습니다. CNN 은 많은 Spatial Filter 들을 Convolution 해서 그에 대한 응답값들을 모아서 Convolution 하는 것이니까요.
그리고 Non - local filter 은 그러한 지역적인 boundary 를 깨고, 하나를 해도 전체적으로 정보를 수집하여 결과를 내는 것이므로 Self-Attention 과 유사하다고 할 수 있습니다.
Non - local Neural Networks
2018년, CVPR 에 <Non-local Neural Networks> 라는 이름의 논문이 발표되었습니다.
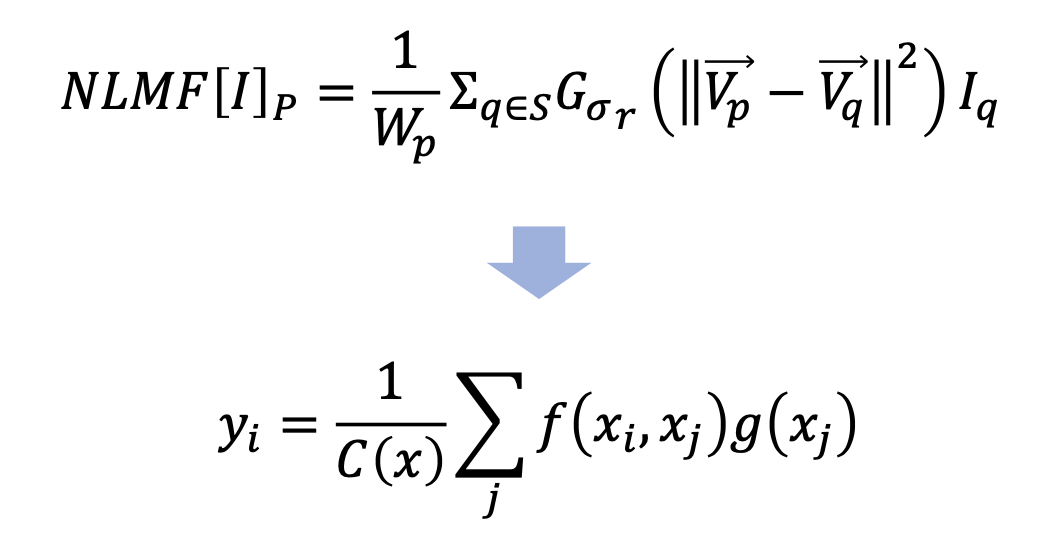
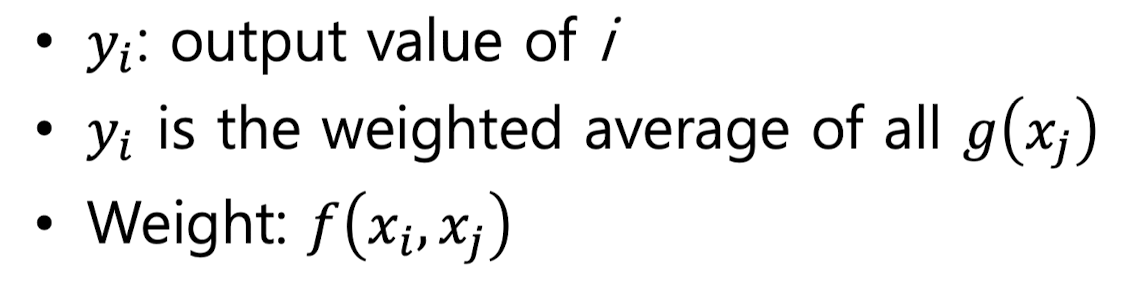
위의 수식이 Non - local Filter 이고, 아래 수식이 Non - local Neural Network 의 Formula 라고 할 수 있습니다. 위의 수식에서 x 가 pixel 이라고 하면, 아래 수식의 x 는 Feature 라고 할 수 있습니다.
i 번째 Feature 를 이용해서 non-local operation 을 통해 나온 y i 번째 값을 얻기 위해서는 ,
나 말고 다른 j 들의 어떤 functional 한 값과, j의 임베딩을 곱해서 sum 함으로써 값을 얻을 수 있습니다.
나와 비슷한 것들을 사용하겠다는 겁니다.
Non - local Block
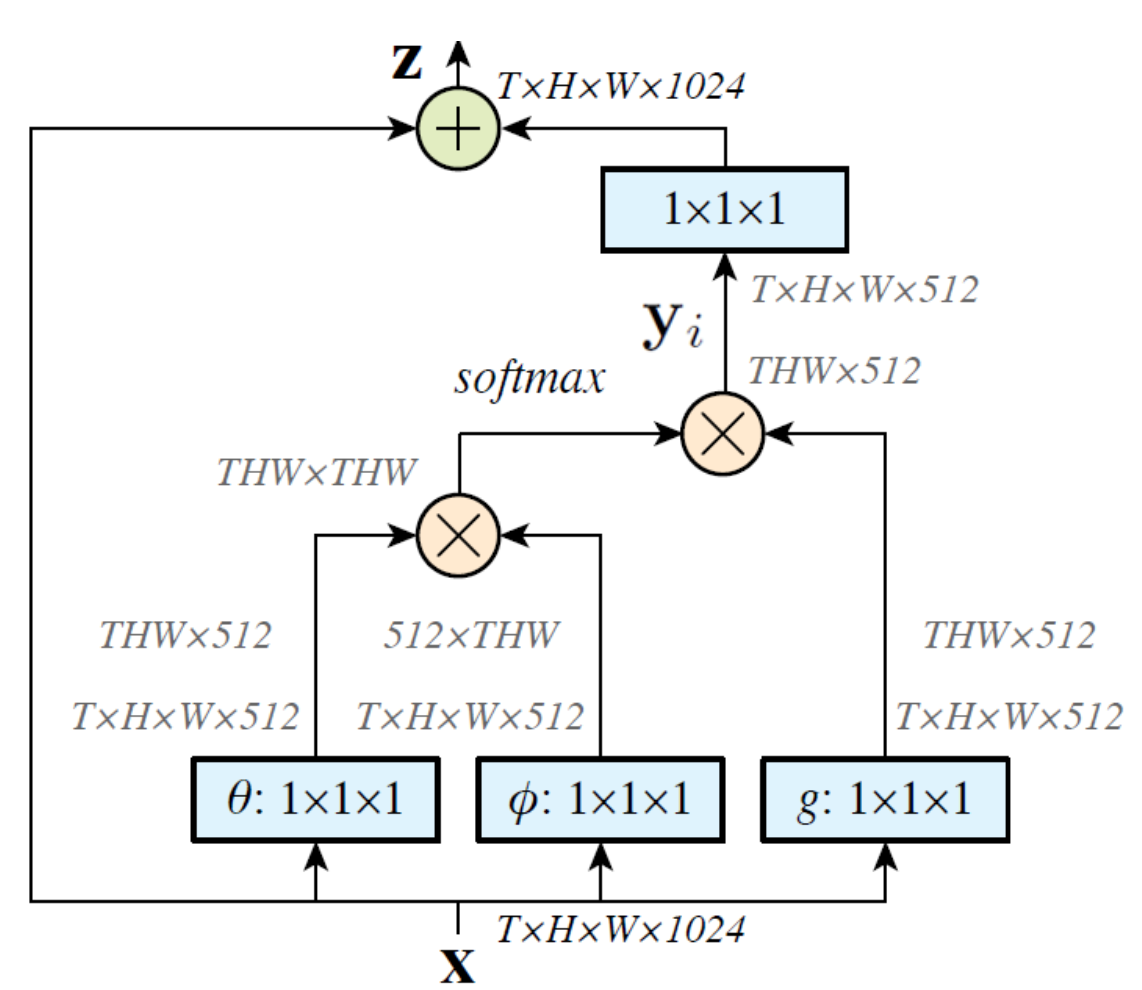
Self - Attention

Self - Attention 은 Non-local block 의 implementation 이라고 할 수 있습니다. 그런데 이게 대체 무슨 맥락에서, 어떤 논리적인 이유로 "잘 된다" 라고 하는 것일까요 ?
Self - Attention 을 할 때는 항상 쿼리, 키, 밸류가 나옵니다. 그러면 이것들이 과연 무엇을 의미하는 걸까요 ?
- Query
- 내가 알고 싶어 하는 것. (target)
- Key
- Python Dictionary 처럼, Key 와 Value 는 한통속 (Pair) 입니다.
- Value
예를 들어 봅시다.
1. Museum Example
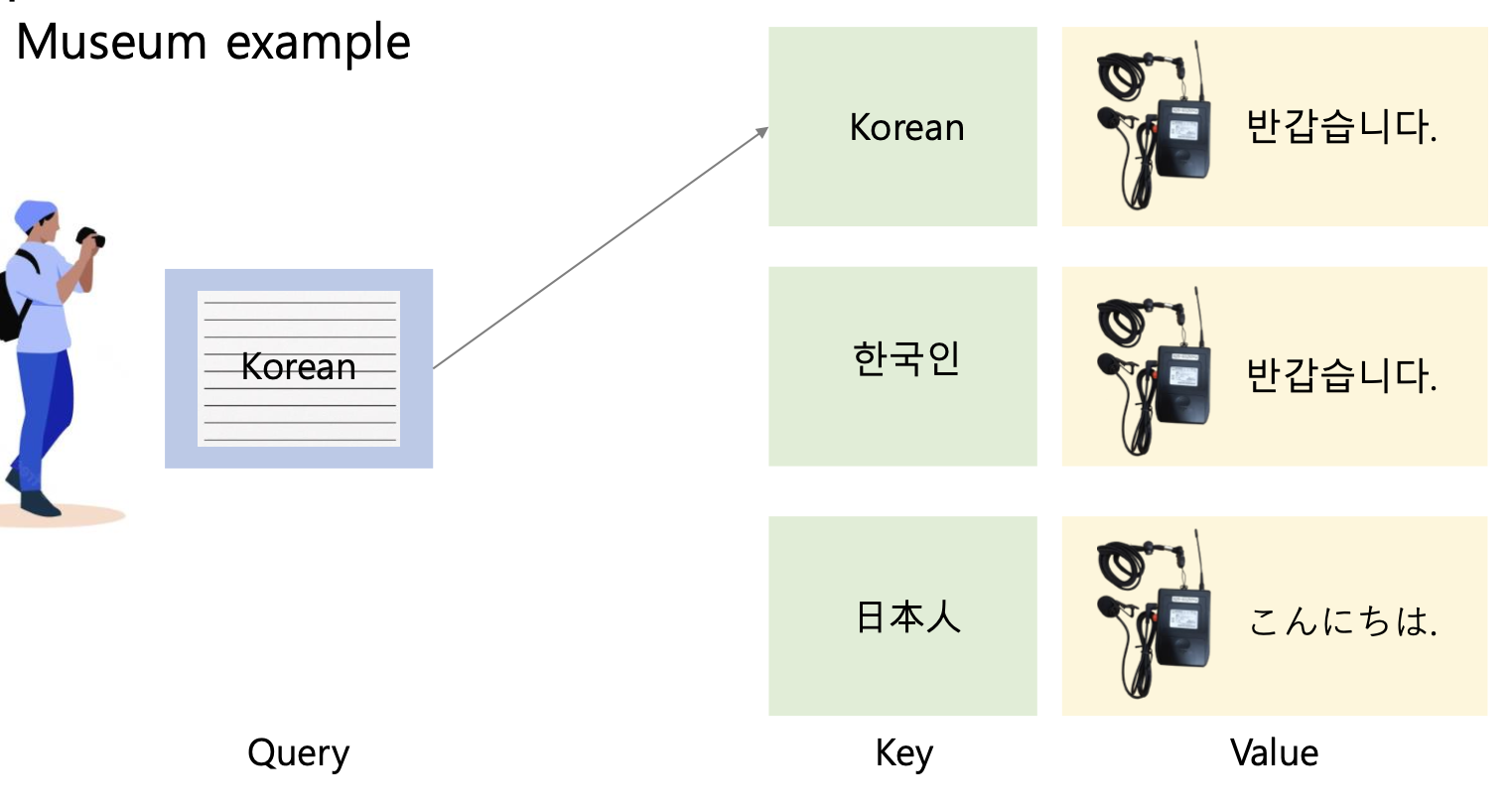
여러분들이 루브르 박물관에 여행을 갔다고 생각해 봅시다. 여러분들이 "어느 나라 사람인지" 적어서 내면, 거기에 맞는 통역기를 박물관에서 제공해 줍니다.
만약 여러분이 "Korean" 혹은 "한국인" 이라고 적어서 내면 한국어 통역기를 주고, "일본인" 이라고 적어서 내면 일본어 통역기를 줍니다.
이때
- 쿼리 : 내가 제출해서 낸 것
- 키 : 쿼리와 함께 매칭하는 것들, 즉 쿼리와 똑같은 지 아닌지 판별하는 애들
- 밸류 : 키에 해당하는 컨텐츠
라고 할 수 있습니다.
2. Subway Example
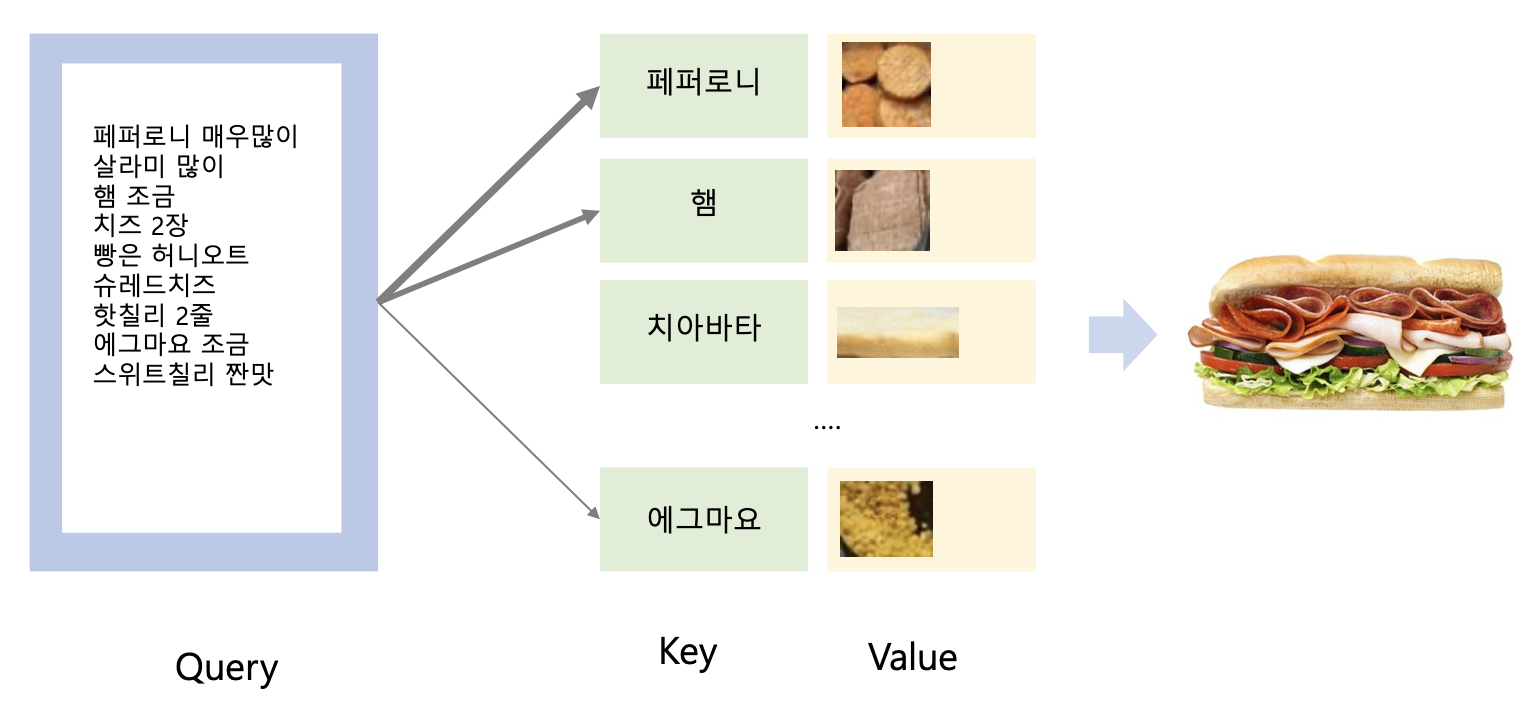
아까 박물관 예제 처럼, query 하나에 key 가 deterministic 하게 매칭 되는 경우도 있겠지만, 어떨 때는 probabilistic 하게 매칭되는 경우도 있을 것입니다. (페퍼로니는 많이, 에그마요는 조금...)
따라서 이 예제에는 확률에 대한 고려가 포함됩니다. 따라서 query 에 따라서 weight 를 다르게 줍니다.
3. Hospital Example
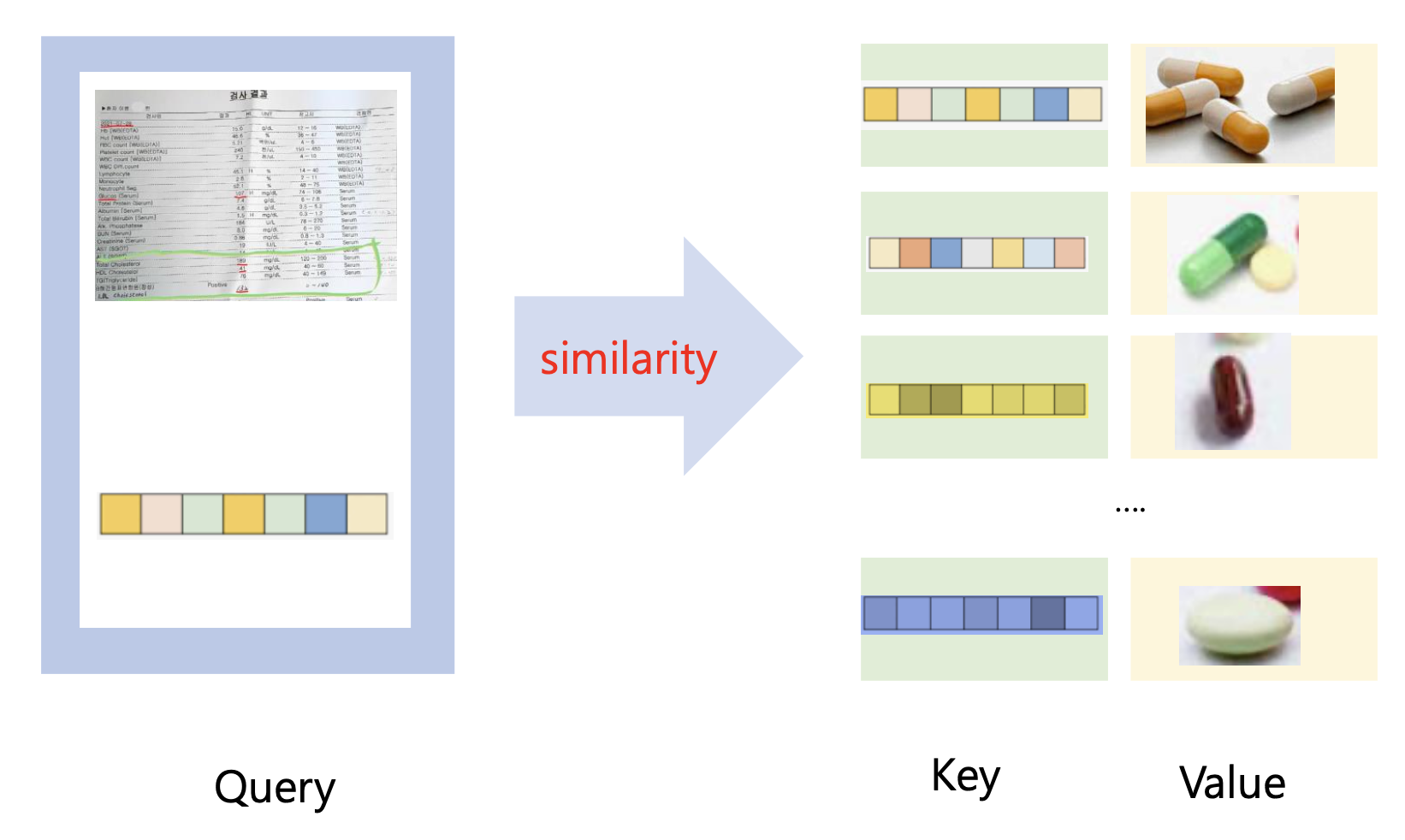
병원 예제는 Embedding 에 대해 다룹니다. 예를 들어 피 검사를 했다고 했을 때, 피 검사 결과와 <고열> 벡터 사이의 유사성, <감기> 벡터 사이의 유사성... 등을 비교해서 유사성이 높은 질병에 관해서는 약을 많이 주고, 유사성이 낮은 질병에 관해서는 약을 적게 주는 처방을 할 수 있겠습니다.
따라서 말 하고 싶은 것은, 쿼리와 키가 물리적인 실제 뿐 아니라, 특징들로써도 비교될 수 있다는 것입니다. 밸류도 또한 object 가 아닌 어떤 information 이 될 수도 있습니다.
쿼리는 또한 여러개가 될 수도 있습니다.
Self - Attention

지금까지 말씀드린 것은 전부 Cross Attention 입니다. Query 를 만들어내는 값들과, (Key, Value) 를 만들어 내는 값들이 다르면 Cross Attention 이라고 합니다.
Self Attention 은 Query, Key, Value 가 모두 하나의 입력으로부터 나오는 것입니다.
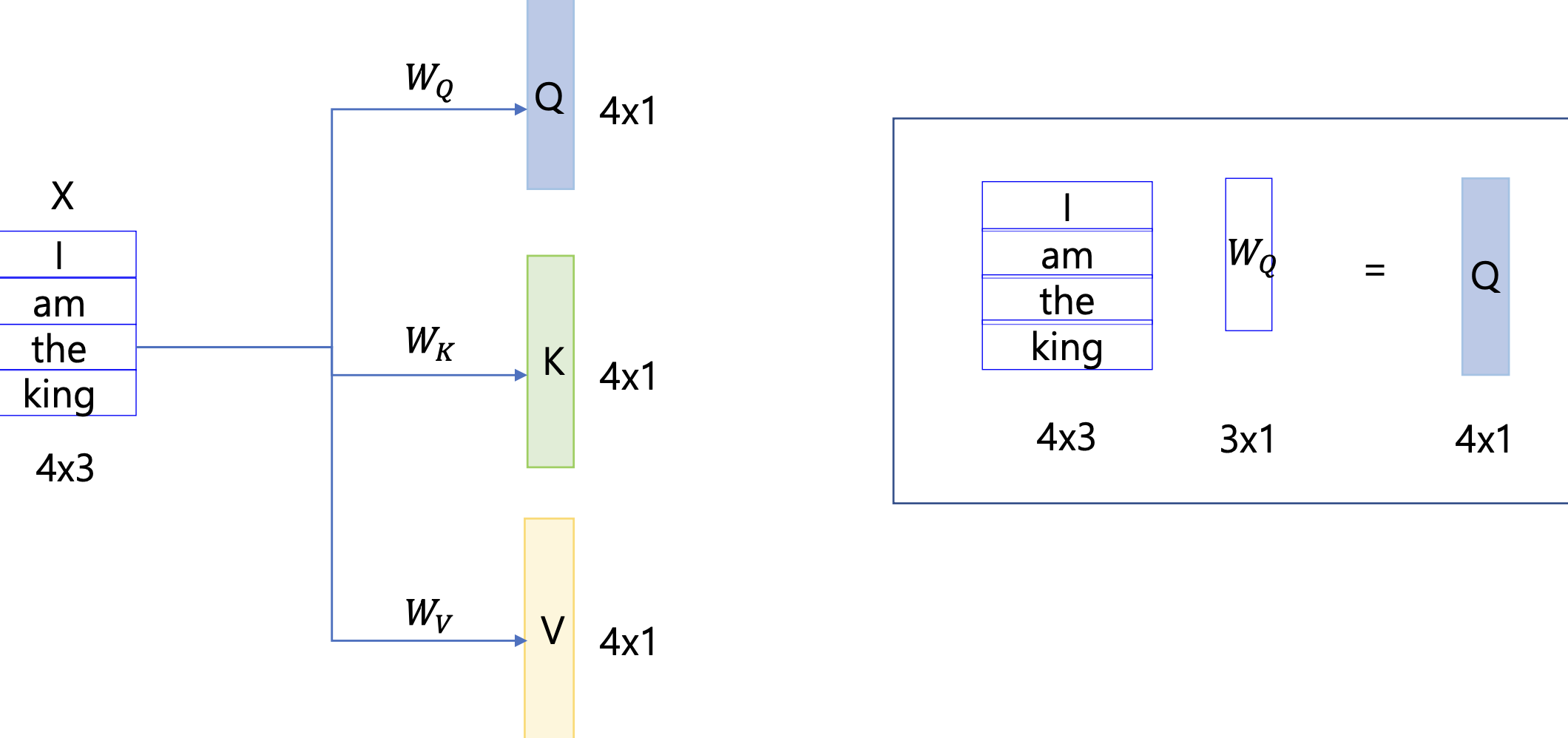
word embedding 을 하는 경우를 예시로 들어 봅시다.
"I am the king" 문장이 있을 때, 이 문장은 단어가 4개고 하나의 단어를 3 - dimension 으로 embedding 을 한 것입니다. 여기서 W 는 3개짜리 필터라고 생각하면 됩니다.
모든 word 에 대한 쿼리 값들을 하나의 스칼라 값으로 만들어서 붙이면 Q 가 됩니다. V, K 도 마찬가지입니다.

그리고 Q와 K 에 대한 Similarity Score 를 구합니다. 각각의 element 들은 Qi 와 Ki 의 유사도를 의미합니다. (유사도는 곱했을 때 값이 크면 유사도가 크다고 합니다.)
그래서 최종적으로는, 유사도가 높은 애들을 많이 갖고 오는 식으로 Non-local filter 와 유사하게 계산됩니다.
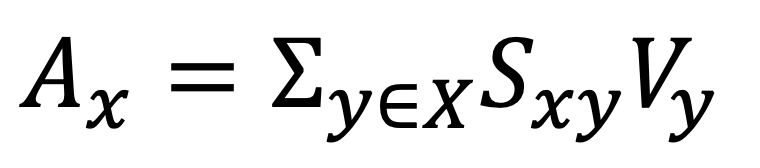
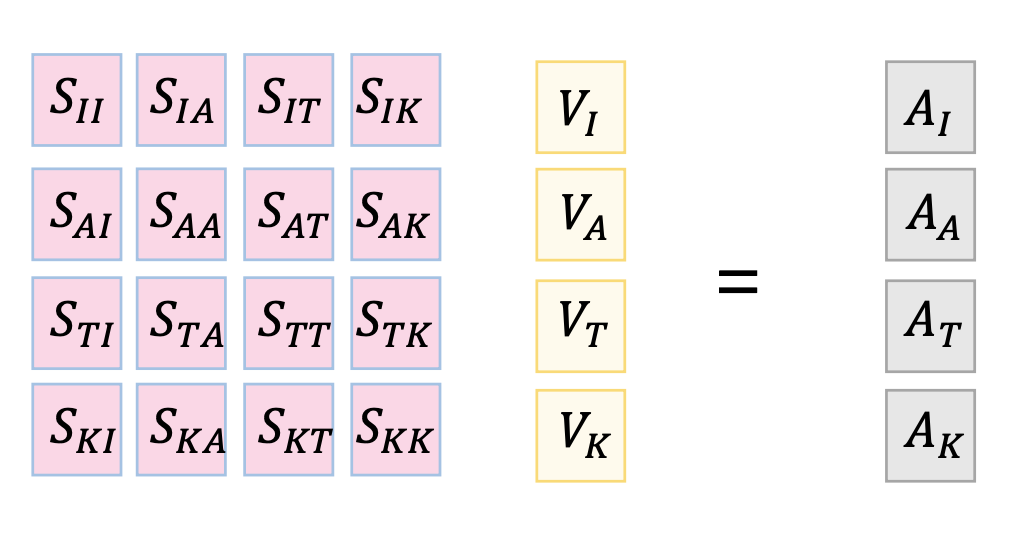
위 내용은 경희대학교 소프트웨어융합학과 황효석 교수님의 2023년 <심층신경망을 이용한 로봇 인지> 수업 내용을 요약한 것입니다.
'딥러닝' 카테고리의 다른 글
| 큰 이미지에서 동작하는 ViT : Swin Transformer (0) | 2023.10.04 |
|---|---|
| 어텐션을 비전에 : ViT (Vision Transformer) (0) | 2023.10.02 |
| Transformer 완전 정복하기😎 (0) | 2023.09.25 |
| 어디에 주목할 것인가 ? : Spatial Attention - STN (Spatial Transformer Network) (0) | 2023.09.16 |
| 무엇에 주목할 것인가 ? Channel attention (0) | 2023.09.12 |
Contents
소중한 공감 감사합니다