딥러닝
MAE : Masked AutoEncoder🤿
- -
K, He, et al. "Masked Autoencoders Are Scalable Vision Learners", ICCV, 2022
- Very simple method, but highly effective
- BERT-like algorithm, but with crucial design changes for vision
- Intriguing properties - better scalability and more from analysis
MAE 같은 형식의 문제가 여기서 처음 나온 건 아닙니다.
우리가 Pretext Task 중에서, Context Prediction 이라는 impainting 태스크가 있었습니다. 또한 Transformer 에서 언급했던 Pixel GPT 도 있습니다.
그런데 2022년에 나온 MAE 가 많은 주목을 받았던 이유에는 크게 두 가지가 있다고 생각합니다.
1. CNN 을 안 썼기 때문입니다.
CNN은 inductive bias 를 이용하기 때문에 operation 자체가 주변에 있는 애들을 땡겨와야지 연산을 할 수 있습니다.
2. Pixel 과 word 의 차이입니다.
우리가 pixel 을 하나 가리고 그 값을 예측하는 것과 word 를 하나 가리고 그 word 를 예측 하는 것은 사실 다른 문제입니다. word 하나는 상당히 많은 high semantic 정보를 가지고 있습니다.
이런 연구의 흐름 상, CNN 이 아닌 Transformer 를 사용하게 되면서 위치 상의 관계로 무언가를 예측하는 게 아닌 다른 방식으로 Attention 을 예측하는 방식이 적용되었습니다.
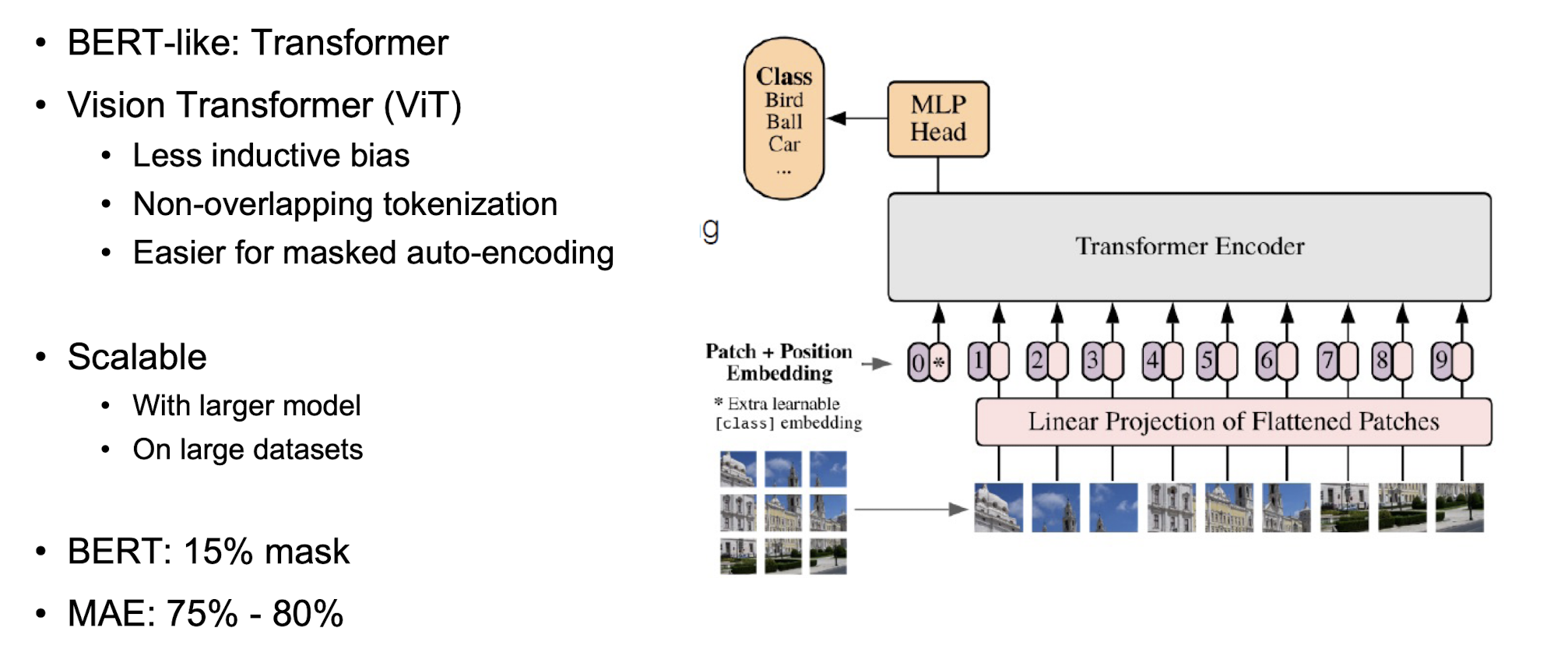
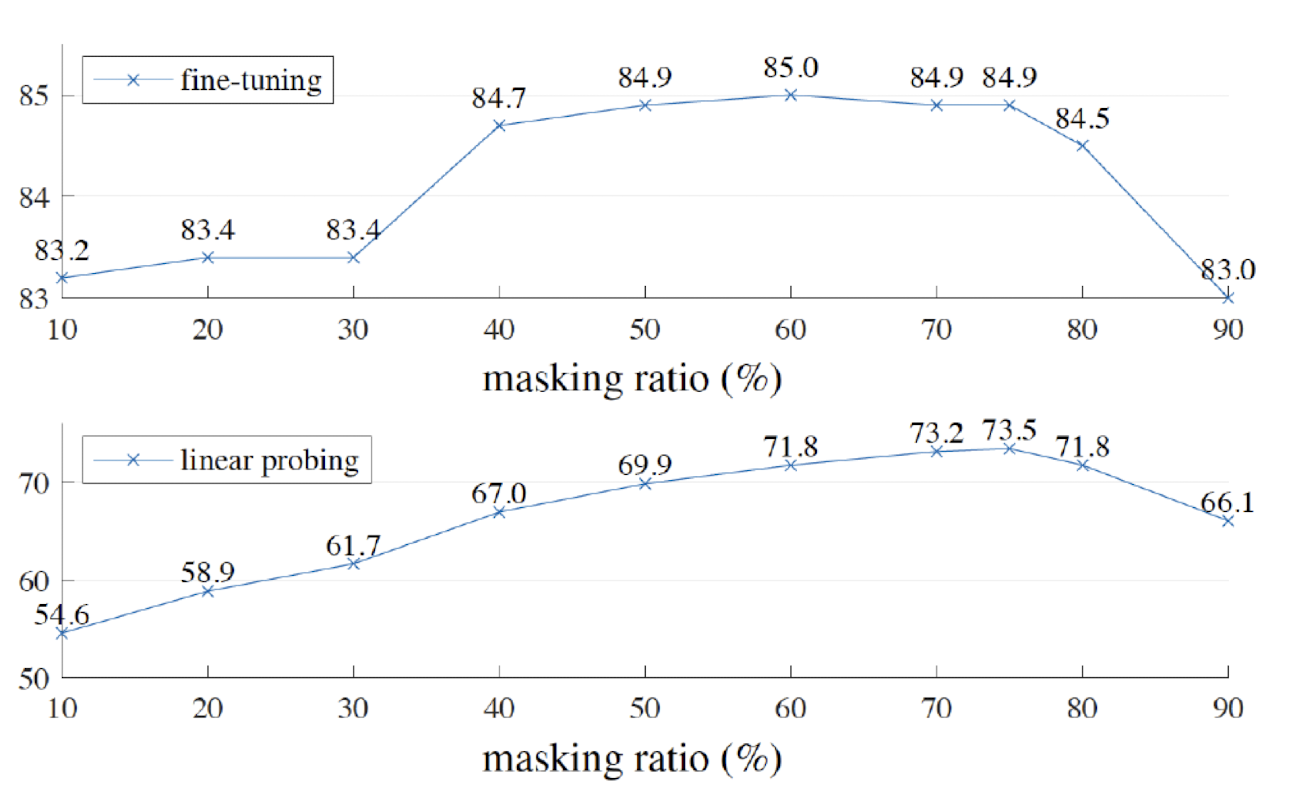
MAE 에서 신기한 것은 Masking 비율입니다. BERT 의 경우, 문장이 있으면 10~15% 정도 가립니다. 그런데 MAE 에서는 10% 를 지울 때 보다 70%를 지웠을 때 더 성능이 좋습니다.
그 이유는 , 말하자면 "힌트를 안 주면 학생들이 더 강인해진다" 는 것입니다. 10%만 Masking 을 했다면 이 네트워크는 무엇을 배우게 될까요 ? 네트워크가 공백 사이들의 정보를 익히려고 하게 될 것입니다.
하지만 70% 를 가려버린다면 어떻게든 드러난 부분들의 semantic 한 정보를 획득하는 방향으로 네트워크가 학습하게 됩니다.
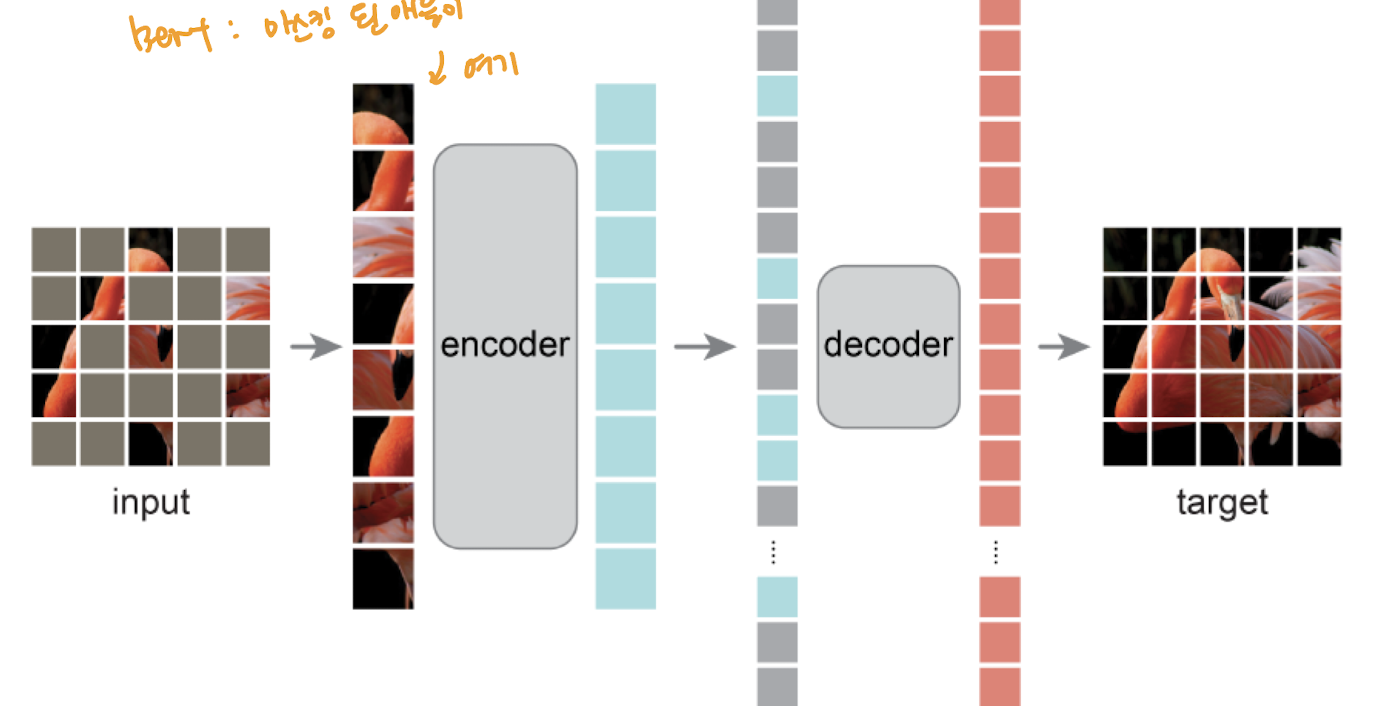
모양 자체는 매우 간단합니다. input 에 masking 을 하면, masking 한 애들은 빼고 encoder 에 집어넣고, encoder 에 대한 최종적인 output vector 들을 얻게 됩니다.
이후 이 벡터들을 projection 시켜서 masking 된 애들을 복원을 하고 decoding 을 합니다.
여기서 BERT 랑 다른 점은, BERT 에서는 Masking 된 애들을 encoder에 넣습니다.
만약 encoder 에 mask 된 패치들을 집어넣게 되면, 나중에 네트워크가 "이 패치는 마스크다" 라는 것을 신경쓰면서 학습을 하게 될 텐데, 문제는 실제 쓸 때는 마스킹을 하지 않는다는 것입니다. 마스크가 있을 때 학습을 하고 마스크 없이 inference 를 하는 것 보다는, 아예 학습을 할 때 마스크 안 된 애들을 학습 하는게 좀 더 성능이 낫지 않겠냐는 것입니다.

사실 80% 를 가리긴 하지만, mask 를 바꿔서 랜덤으로 다양한 마스크를 적용해서 학습을 합니다. 그거 자체로 augmentation 이 되는 것입니다.
위 내용은 경희대학교 소프트웨어융합학과 황효석 교수님의 2023년 <심층신경망을 이용한 로봇 인지> 수업 내용을 요약한 것입니다.
'딥러닝' 카테고리의 다른 글
| Domain Generalization (0) | 2023.12.06 |
|---|---|
| Backdoor Attack on Self-Supervised Learning (1) | 2023.11.24 |
| Contrastive Learning : BYOL (Bootstrap Your Own Latent) (2) | 2023.11.20 |
| Contrastive Learning : Moco (Momentum Contrast) (0) | 2023.11.16 |
| Self - Supervised Learning : Contrastive Learning (0) | 2023.11.09 |
Contents
소중한 공감 감사합니다