딥러닝
Backdoor Attack on Self-Supervised Learning
- -
Backdoor Attack은 Adversarial Attack 의 한 종류입니다.
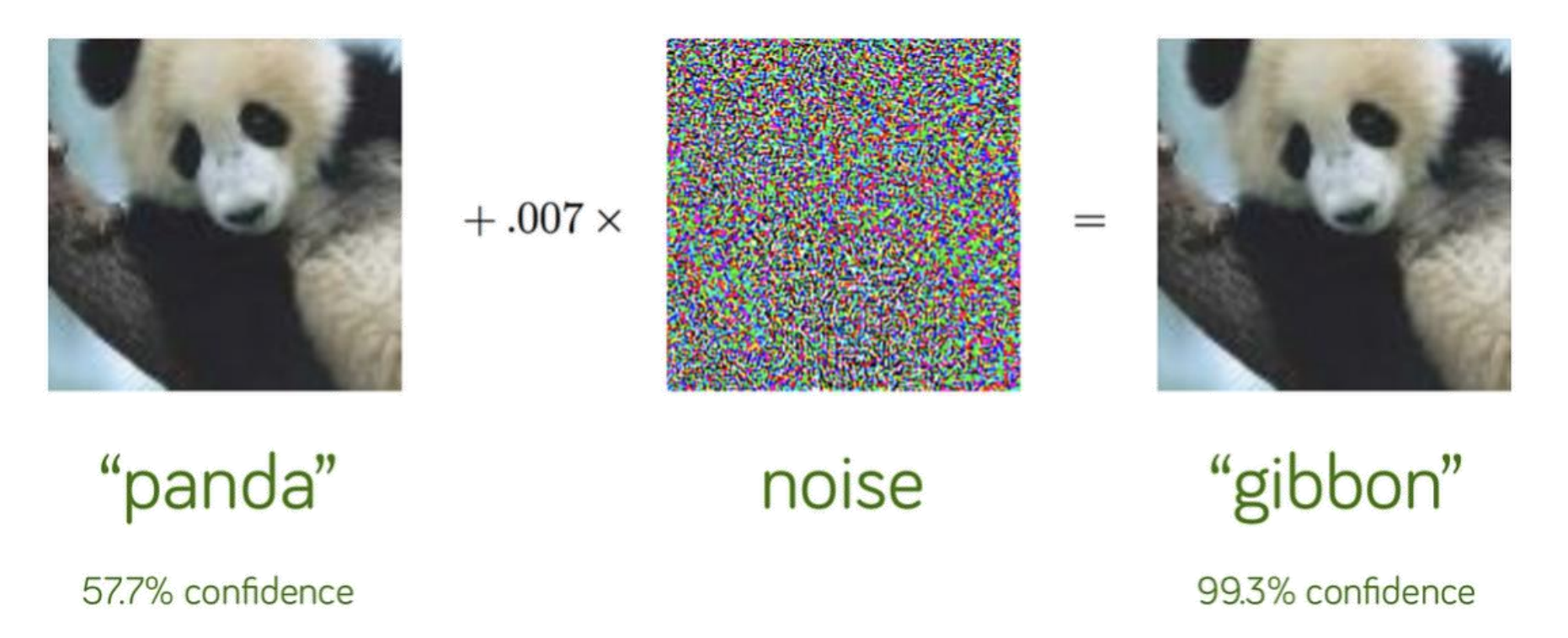
위와 같은 Attack 을 Evasion Attack 이라고 합니다. 우리가 실제로 모델을 학습시킬 때 사용하는 게 아니라, 학습된 모델을 테스트할 때 테스트 이미지를 조작해서 잘못된 결과를 내도록 하는 것입니다.
Backdoor Attack
Backdoor Attack 은 "트로이 목마" 처럼 무언가를 심어 놓는 것입니다. 이미 학습을 할 때부터 심어 놓게 됩니다.
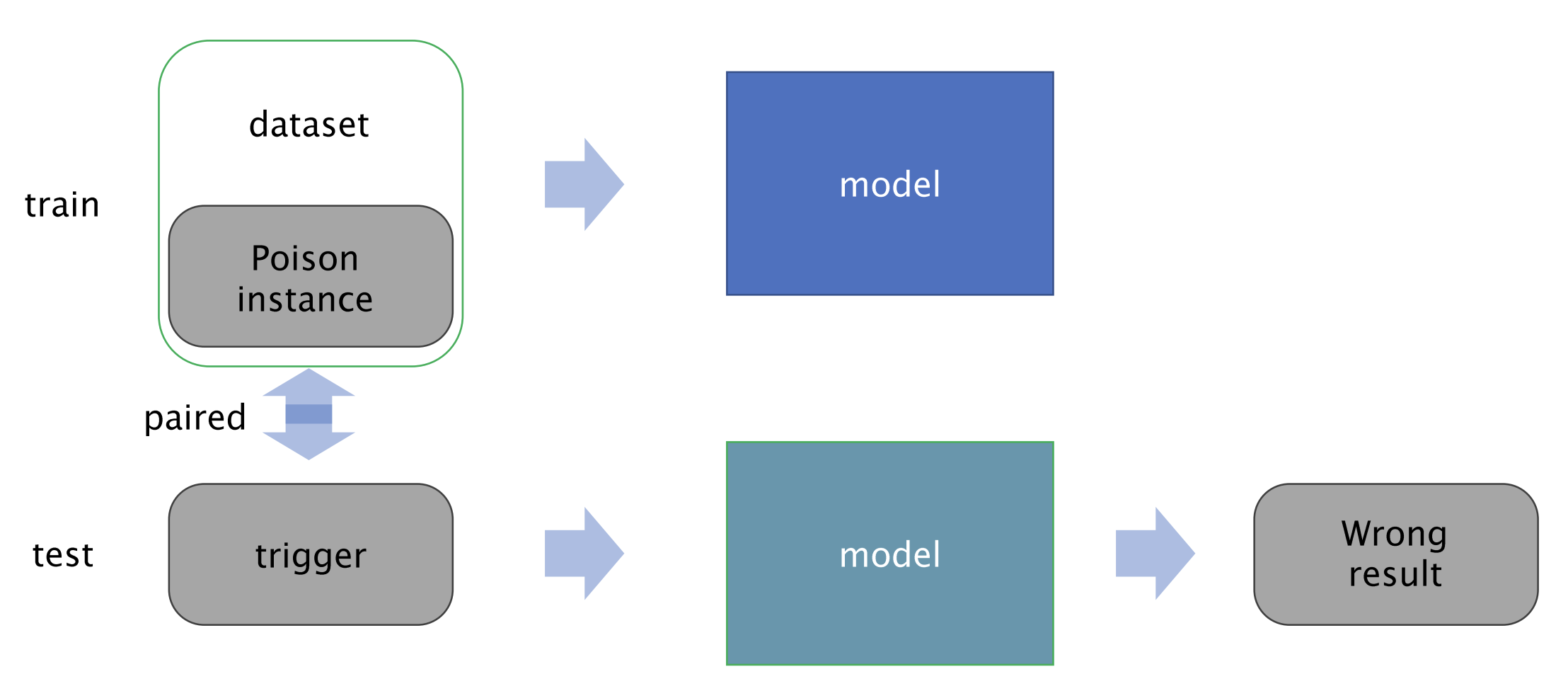
이때 Poison instance 는 우리가 학습을 시키는 데이터셋에 오염된 instance 를 추가시키거나, 기존에 있던 데이터셋을 조금 변형시키는 것입니다. 예를 들어 데이터셋이 10,000 장이면 100 장 정도에 perturbation 이나 의도를 가진 데이터셋을 집어 넣는 것입니다.
그러면 이 모델은 학습할 때부터 poison instance 를 포함한 데이터셋을 학습하게 되는 것입니다. 그러면 이는 어떤 결과를 초래할까요 ?
Poison instance 는 마찬가지로 사람의 눈으로 보기에는 정상적으로 보입니다. 하지만 우리가 처음에 instance 를 만들 때부터 이는 trigger 와 연동이 되도록 만들어집니다. poison instance 는 trigger 에 대해서는 잘못된 결과를 내놓게 됩니다.
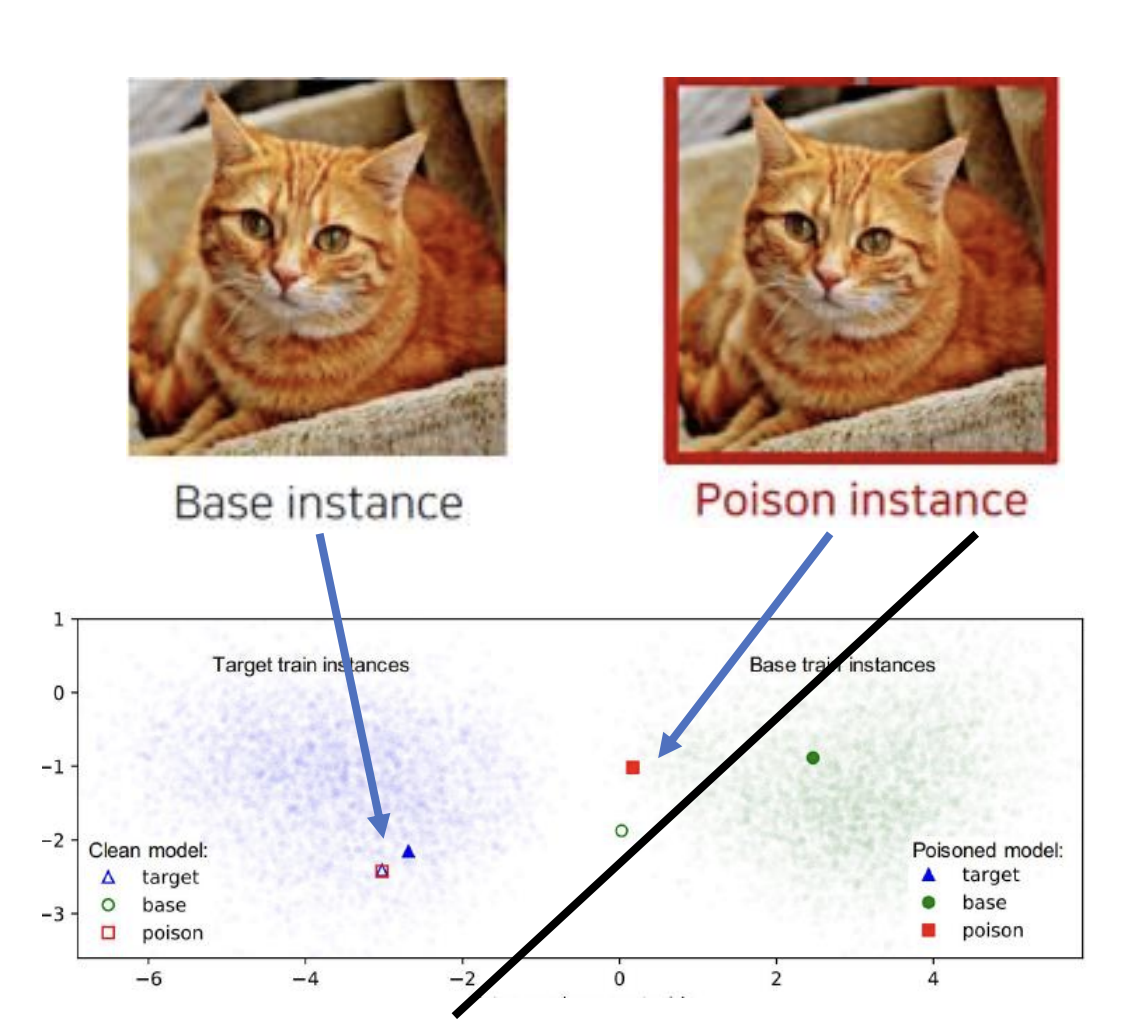
Base instance 와 Poison instance 는 사람의 눈으로는 같은 클래스를 가지는 이미지들입니다.
그런데 Feature Space 에서 보자면 이 둘은 다른 feature 들을 가집니다. Poison instance 는 Trigger 와 유사한 feature 를 가집니다.
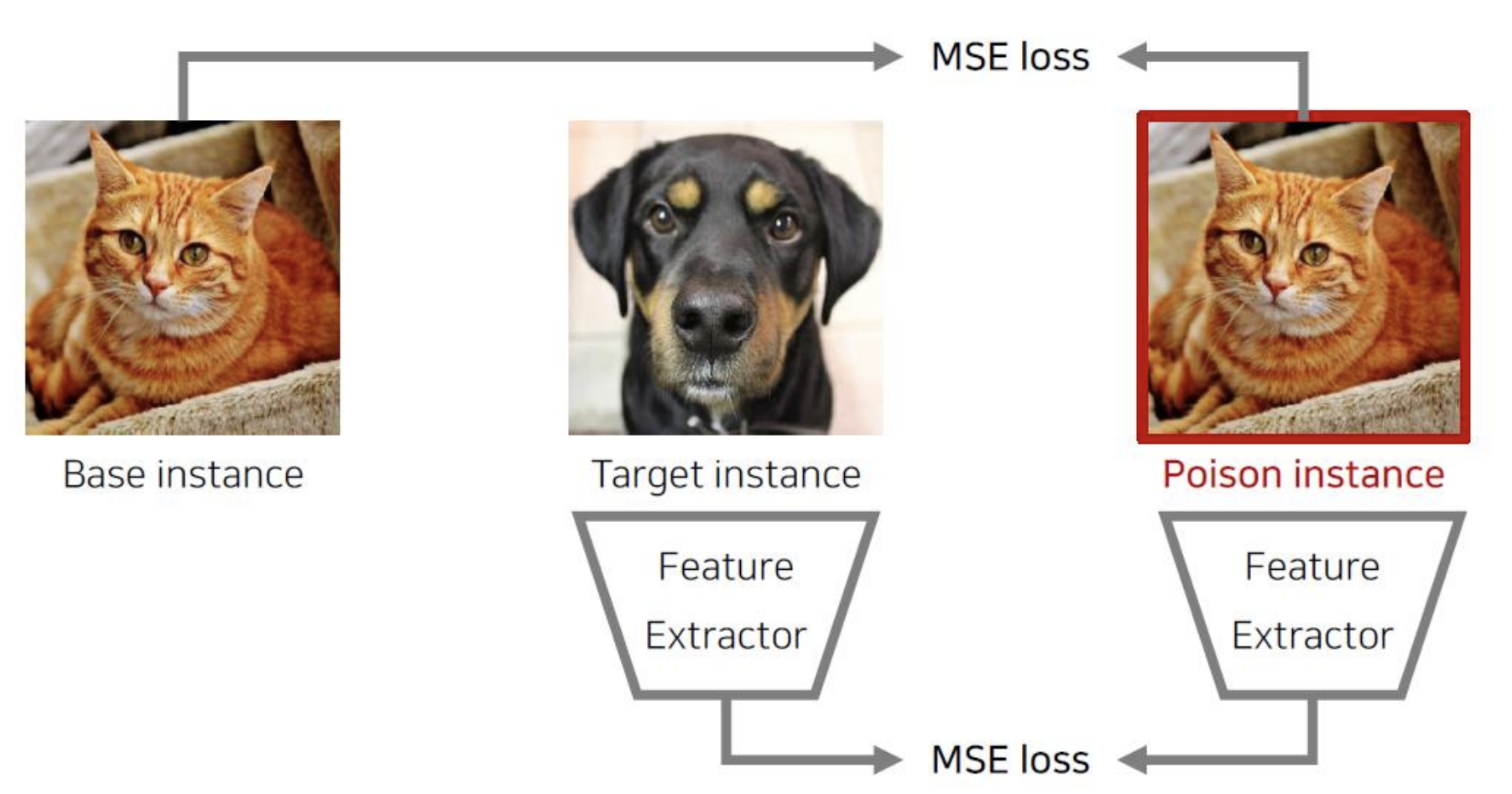
Base instance 와 Poison instance 를 가지고 모델을 학습하지만, Feature extractor 를 통해 보면 target instance 와 같은 feature 가 나오도록 만들어 냅니다.
Poison instance 를 생성할 때는 Base instance 와 MSE loss (픽셀들 간의 차이) 가 적도록 생성하고, Feature 들끼리의 MSE loss 는 target instance 와 비교했을때 적어지도록 학습합니다.
그러면 실제로 두 Feature 는 멀리 떨어져있지만, 두 Feature 를 모두 포함하여 CAT 이라는 클래스를 결정하도록 분류기가 학습하게 됩니다. 그러면 나중에 DOG 그림을 넣었을 때, Feature 이 poison instance 와 유사하게 추출될 것이므로 이 분류기는 DOG 도 CAT 이라고 분류하겠죠 ?
Backdoor Attacks on Self - Supervised Learning
이런 방식이 Self - Supervised Learning 에서도 큰 효과를 가진다는 것이 2022년 CVPR 에서 발표되었습니다.
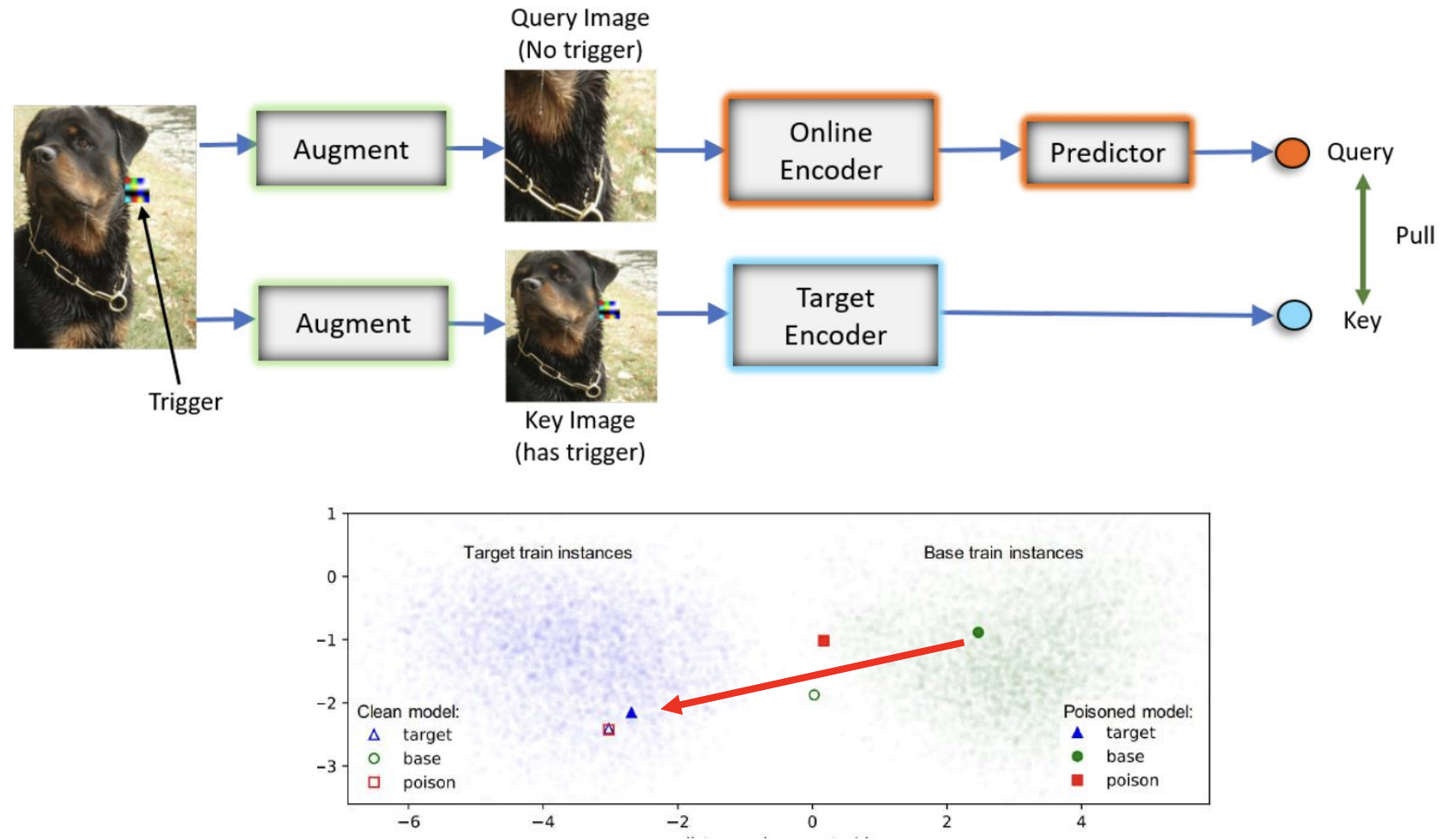
이 논문에서는 이미지에 trigger 라고 하는 패치를 삽입 합니다.
여기서 제안한 Backdoor attack 은 크게 4가지 단계를 거칩니다.
- Generate poisoned images : 내가 속이고 싶은 카테고리에 패치들을 다 집어넣는다.
- Self-supervised pre-training
- Feature Transfer to supervised task
- Test time
결과적으로 이와 같이 일반적인 사진을 넣었을 때는 잘 분류하지만, 패치 이미지를 삽입한 이미지에 대해서는 모두 "사냥개" 카테고리로 분류하게 됩니다.

그런데 여기서 말하는 것은, 우리가 ImageNet이라고 하는 것도 사실 인터넷에서 긁어 모은 데이터셋입니다. 실제로 인스타그램에 올라온 사진들만 모아서 만든 데이터셋도 있습니다.
그래서 우리가 어떤 표식 (Patch) 을 한 사진을 인터넷에 올리면, 그 사진이 데이터셋에 포함될 확률이 굉장히 높다는 것입니다.
논문에서는 눈에 보이는 패치를 사용했지만, 사람 눈에 보이지 않는 표식을 사용하더라도 이러한 효과를 낼 수 있습니다.


위 내용은 경희대학교 소프트웨어융합학과 황효석 교수님의 2023년 <심층신경망을 이용한 로봇 인지> 수업 내용을 요약한 것입니다.
'딥러닝' 카테고리의 다른 글
| Domain Generalization : Data Manipulation Methods (1) | 2023.12.06 |
|---|---|
| Domain Generalization (0) | 2023.12.06 |
| MAE : Masked AutoEncoder🤿 (1) | 2023.11.23 |
| Contrastive Learning : BYOL (Bootstrap Your Own Latent) (2) | 2023.11.20 |
| Contrastive Learning : Moco (Momentum Contrast) (0) | 2023.11.16 |
Contents
소중한 공감 감사합니다