강화학습
Policy Gradient : REINFORCE
- -
기존의 tabular한 방법론들은 state value나 action value 를 사용해서 policy를 생성했습니다. 즉, policy 는 Q-table을 통해서 (ex. epsilon-greedy) 만들어졌습니다. 하지만 Policy Gradient부터는 policy자체를 추정하게 됩니다.
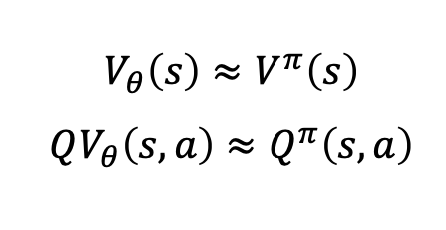

그래서 Value-based Learning과 Policy-based Learning은 크게 다음과 같이 나눌 수 있습니다.
Value-based는 뉴럴넷이나 테이블을 이용해서 Q-value를 계속해서 학습 해 나가고, 이 Q-value를 이용해서 Policy를 정하는 것입니다.
Policy-based는 말 그대로 value를 따로 구하지 않고 policy만 학습을 하는 것입니다. 그리고 Actor-Critic은 둘 다 사용하는 것입니다. Value도 추정하고 Policy도 추정합니다.
그러면 policy를 바로 학습하는 것은, value를 통해서 policy를 구하는 방법에 비해 어떤 장점이 있을까요 ?
장점
- 강화학습의 궁극적 목표는 "주어진 환경에서 내가 어떤 행동을 해야 하는지" 이기 때문에, Policy를 바로 학습한다는 것은 실제 목적에 부합하는 행위입니다.
- Value를 학습하는 것 보다 좀 더 수렴이 잘 됩니다.
- High-dimensional or continuous action spaces에서 효과적입니다.
- stochastic policy를 학습할 수 있습니다.
단점
- local maximum에 빠질 수 있습니다.
- variance가 좀 큽니다.
예제
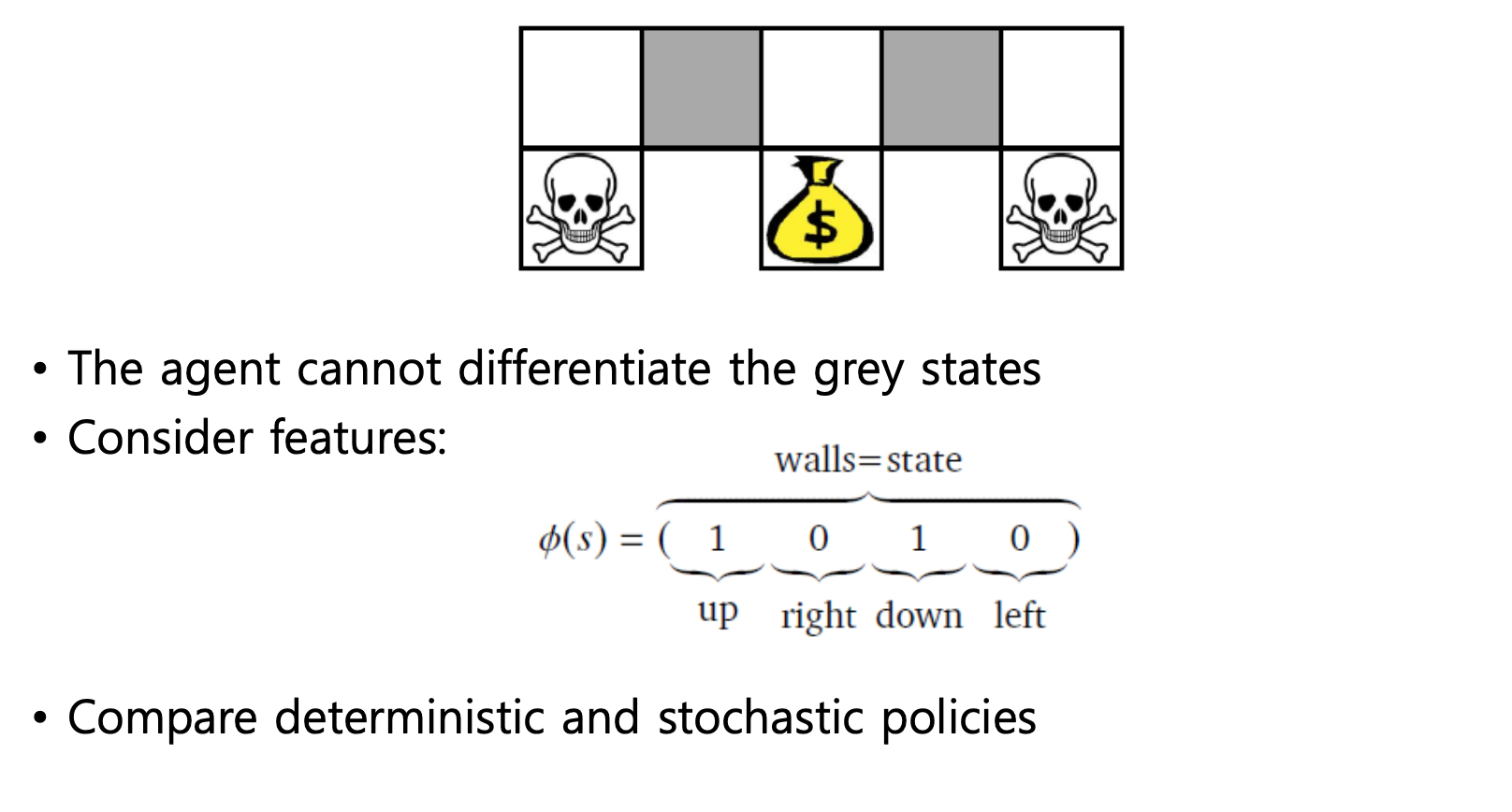
해골로 들어가면 죽는 것이고, 돈주머니가 있는 곳에 들어가면 Reward가 큰 Grid world 입니다.
지금까지 다뤘던 Grid world는 Fully observable state였습니다. 즉, 내가 어떤 위치에 있으면 그 위치에 대한 state가 뭔지 알고 있다는 것입니다. 하지만 우리가 실제 어떤 문제를 풀 때에는 그렇게 주어지는 경우는 별로 없습니다. 내가 Sensing할 수 있는 범위 내에서만 주변 환경을 인지할 수 있습니다.
그래서 Aliased Grid World에서는 <위, 우측, 아래, 좌측> 이 막혔는지 / 막히지 않았는지 만 가지고 state를 정의합니다. 그런 식으로 정의를 한다면, 회색 두 칸은 state가 동일하게 됩니다.
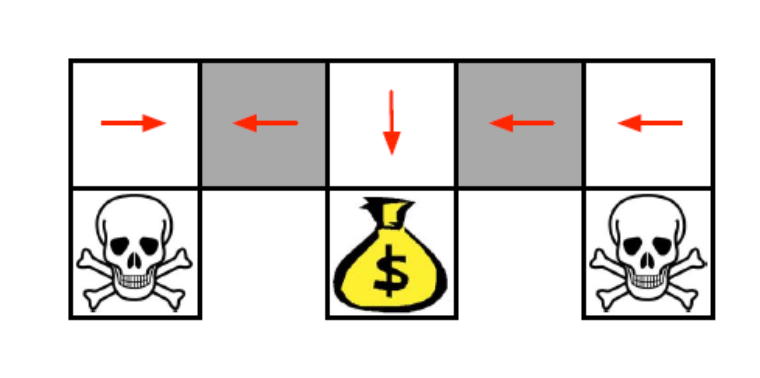
그래서 State만 가지고 deterministic하게 policy 를 결정해버린다면, 회색 두 칸의 policy가 동일하기 때문에 계속 왔다갔다 (stuck)하게 되겠죠 ?
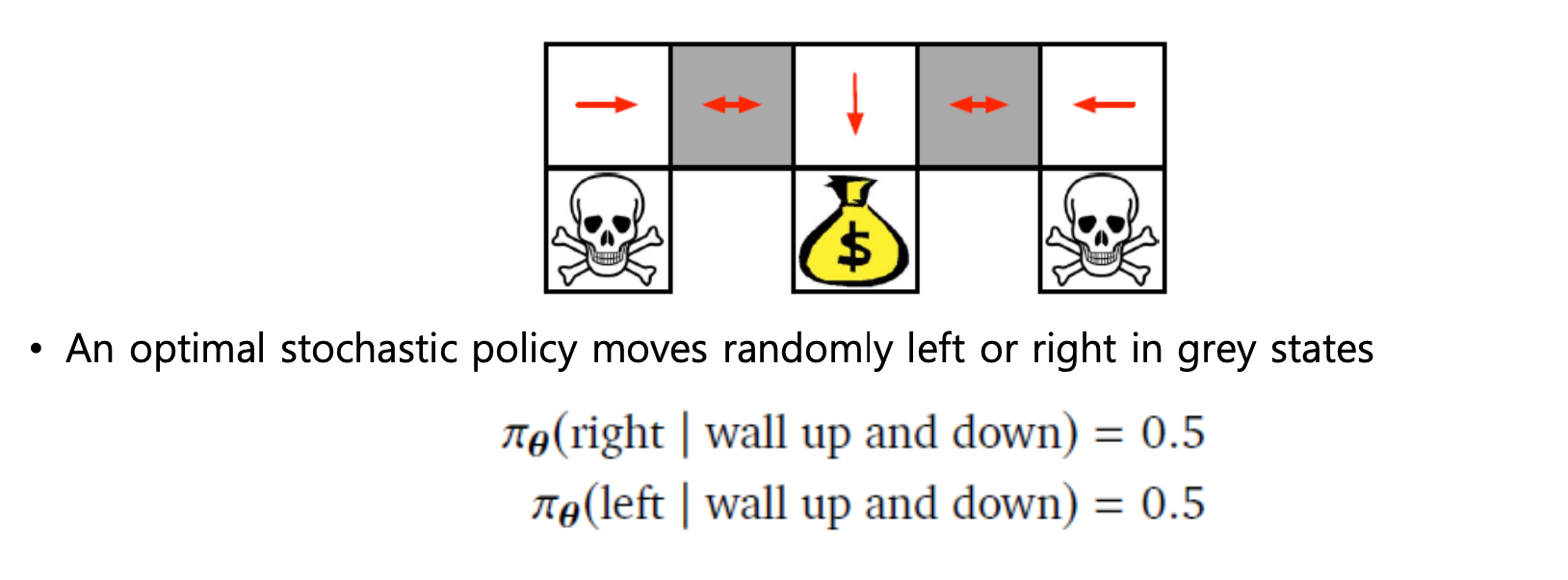
이에 반해 Stochastic Policy 의 경우, 각각의 policy에 대해 확률적으로 정의를 합니다.
그러면 지금 우리가 하려고 하는 것은 "뉴럴넷을 이용해서 Policy를 직접 학습 시키겠다" 는 것입니다.

여기서 π는 θ라는 파라미터를 가진 뉴럴 네트워크입니다. 이는 (s, a)를 입력으로 받았을 때 어떤 확률값을 output으로 주게 됩니다.
이렇게 학습한 뉴럴넷을 평가하기 위해서는 기준이 필요합니다. 강화학습에서 어떤 policy가 좋은지 안 좋은지를 어떻게 평가할까요 ? 이 policy를 따라서 행동을 했을 때 reward를 많이 획득하는, 혹은 return이 큰 policy가 좋은 policy 입니다.
그래서 Objective Function , 즉 목적 함수를 J 라고 하면 J 는 Return의 기댓값인 value로서 정의되며, 이를 최대화하는 것이 우리의 목표입니다.
J(θ)를 크게 만드는 θ 값을 찾아야 합니다. 그리고 상황에 따라 J(θ)를 다르게 정의할 수 있습니다. 이때 stationary distribution은 특정 state 에 있을 확률 분포를 의미합니다.
위 내용은 경희대학교 소프트웨어융합학과 황효석 교수님의 2023년 <강화학습> 수업 내용을 요약한 것입니다.
'강화학습' 카테고리의 다른 글
| Dynamic Programming (0) | 2025.01.31 |
|---|---|
| Markov Decision Process (MDP) & Bellman Equation (0) | 2025.01.30 |
| 강화학습 수업 Navigator (0) | 2025.01.30 |
Contents
소중한 공감 감사합니다