논문 리뷰
DTG : code explained
- -
DTG : Diffusion-based Trajectory Generation for Mapless Global Navigation

GitHub - jingGM/DTG
Contribute to jingGM/DTG development by creating an account on GitHub.
github.com
덧) 이거 실행하면 이케 학습됨 근데 코드에 오타가 있어서 몇 개 고쳐줘야 댐...
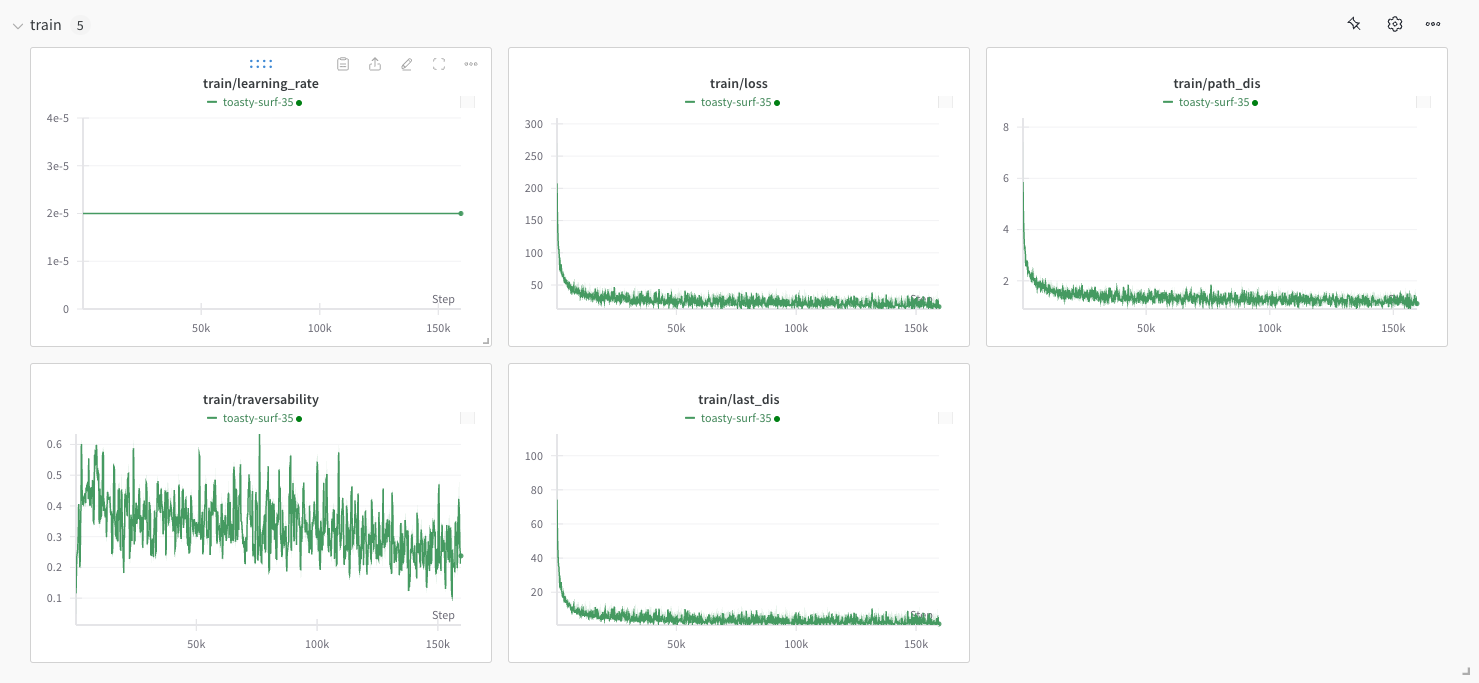
+) 그리고 github에 inference 코드가 공개가 안 되어 있삼... 😡 잉 잉
모델이 최종적으로 예측하는 것
- 출력 차원
- (batch_size, waypoints_num, waypoint_dim)
- waypoints_num : 경로를 구성하는 waypoint의 갯수
- waypoint_dim : waypoint의 차원
- (batch_size, waypoints_num, waypoint_dim)
- 단계
- observation을 encoder를 통해 zd 차원의 latent vector로 변환
- diffusion 모델이 이 latent vector를 조건으로 사용하여 경로를 생성
- 최종적으로 sample 메소드를 통해 노이즈에서 시작하여 점진적으로 실제 경로를 생성
- additional
- use_traversability가 활성화 된 경우 : traversable한 경로로 가기 위한 추가적인 처리 수행
- use_all_paths가 활성화 된 경우 : diffusion process의 중간 단계 경로들도 저장
dataloader
class TrainData(Dataset):
def __getitem__(self, index):
lidar, camera, imu, velocity, trajectory, target, heuristic, local_map, pose, raw_target = self.load_data(index=index)
@jit(nopython=True)
def process_single_lidar(line_pts, distance, lidar_horizons, lidar_angle_range, angle_to_idx, lidar_threshold):
line_values = np.zeros(lidar_horizons)
for i in range(len(line_pts)):
pt = line_pts[i]
dis = distance[i]
if dis > lidar_threshold:
dis = 0
idx = int((np.arctan2(pt[1], pt[0]) + lidar_angle_range / 2.0) * angle_to_idx)
if 0 < idx < lidar_horizons:
if line_values[idx] <= 0.5:
line_values[idx] = dis
else:
if line_values[idx] > dis:
line_values[idx] = dis
return line_values- 각 LiDAR 포인트를 수평 각도에 따라 적절한 인덱스로 매핑
- 특정 각도에서 여러 포인트가 있을 경우, 가장 가까운 거리 값을 저장
- lidar_threshold보다 먼 거리의 포인트는 0으로 처리
- 각 각도에서 가장 가까운 물체까지의 거리만 저장하여 장애물 탐지
models / diffusion.py
from diffusers.schedulers.scheduling_ddpm import DDPMScheduler
class Diffusion(nn.Module):
def __init__():
self.noise_scheduler = DDPMScheduler(beta_start=cfg.beta_start, beta_end=cfg.beta_end,
prediction_type="sample", num_train_timesteps=cfg.num_train_timesteps,
# clip_sample_range=cfg.clip_sample_range,
clip_sample=cfg.clip_sample,
beta_schedule=cfg.beta_schedule, variance_type=cfg.variance_type)
DDPMScheduler는 Diffusion model의 노이즈 스케줄링을 관리하는 클래스이다.
- 주요 파라미터
- beta_start, beta_end : 노이즈 스케줄의 시작과 끝 값
- num_train_timesteps : diffusion 과정의 총 스텝 수
- prediction_type : 모델의 예측 타입
- sample : 모델이 직접 다음 타입스텝의 샘플을 예측
- epsilon : 모델이 노이즈를 예측 (원본 DDPM 논문에서 사용된 방식)
- v_prediction : velocity 예측
- clip_sample : 샘플 클리핑 여부
- 모델의 출력을 유효한 범위 내로 유지
- 주요 기능
- 각 타임스텝 마다 베타 값을 사용하여 노이즈 양을 조절
- Forward process : 노이즈 추가
- noisy_samples = scheduler.add_nois(original_samples, noise, timesteps)
- Reverse process : 노이즈 제거
- prev_sample = scheduler.step(model_output, timestep, sample).prev_sample
- beta scheduling
- linear : 선형적으로 베타 값 증가
- scaled_linear : 스케일된 선형 증가
- squaredcod_cap_v2 : cosine 스케줄링
self.zd = cfg.diffusion_zd
# configs.py
Diffusion.diffusion_zd = 512 # Latent dimension size
zd는 Diffusion model의 latent dimension을 의미한다.
@torch.no_grad()
def sample(self, observation):
h = self.encoder(observation) # B x 512
h_condition = self.trajectory_condition(h)
B, C = h_condition.shape
trajectory = torch.randn(size=(h_condition.shape[0], self.waypoints_num, self.waypoint_dim),
dtype=h_condition.dtype, device=h_condition.device, generator=None)
all_trajectories = []
scheduler = self.noise_scheduler
scheduler.set_timesteps(self.time_steps)
for t in scheduler.timesteps:
if (self.sample_times >= 0) and (t < self.time_steps - 1 - self.sample_times):
break
t = t.to(h_condition.device)
model_output = self.diff_model(trajectory, t.unsqueeze(0).repeat(B, ), local_cond=None,
global_cond=h_condition)
trajectory = scheduler.step(model_output, t, trajectory, generator=None).prev_sample.contiguous()
if self.use_all_paths:
all_trajectories.append(model_output.clone().detach().cpu().numpy())
output = {
DataDict.prediction: trajectory,
DataDict.all_trajectories: all_trajectories,
}
return output
sample 함수는 학습된 디퓨젼 모델을 사용해서 새로운 경로를 생성하는 메소드이다. 다음과 같은 단계로 이루어진다.
1. 인코딩
2. 초기 노이즈 생성 (크기 : [배치, Waypoint 수, Waypoint 차원]
3. 디노이징
self.encoder = nn.Sequential(
nn.Linear(cfg.perception_in, 1024),
activation_func(),
nn.Linear(1024, 2048),
activation_func(),
nn.Linear(2048, 512),
activation_func(),
nn.Linear(512, self.zd), # 최종적으로 zd 차원으로 압축
activation_func()
)
def forward(self, observation, gt_path=None, traversable_step=None):
h = self.encoder(observation) # B x 512
h_condition = self.trajectory_condition(h)
output = {}
noisy_trajectory, noise, time_step = self.add_trajectory_step_noise(trajectory=gt_path, traversable_step=traversable_step)
if self.use_traversability:
h_condition = torch.concat((h_condition, h_condition), dim=0)
pred = self.diff_model(noisy_trajectory, time_step, local_cond=None, global_cond=h_condition)
output.update({
DataDict.prediction: pred,
DataDict.noise: noise,
DataDict.time_steps: time_step
})
return output
foward는 다음과 같은 단계로 이루어진다.
- 인코딩
- observation을 512차원의 latent vector로 변환
- trajectory_condition 레이어를 통해 조건부 정보로 변환
- 노이즈 추가 단계
- gt 경로에 노이즈를 추가
- 노이즈가 추가된 trajectory, 원본 노이즈, 시간 스텝 반환
- traversability 처리
- Diffusion 모델 예측 (pred)
- 노이즈가 추가된 trajectory를 입력으로 받아 예측
- 출력 생성 (output.update)
model / model.py
class HNav(nn.Module):
def forward(self, input_dict, sample=False):
if sample:
return self.sample(input_dict=input_dict)
else:
output = {DataDict.path: input_dict[DataDict.path],
DataDict.heuristic: input_dict[DataDict.heuristic],
DataDict.local_map: input_dict[DataDict.local_map]}
observation = self.perception(lidar=input_dict[DataDict.lidar], vel=input_dict[DataDict.vel],
target=input_dict[DataDict.target])
generator_output = self.generator(observation=observation, gt_path=input_dict[DataDict.path],
traversable_step=input_dict[DataDict.traversable_step])
output.update(generator_output)
return output
- 역할
- 전체 파이프라인 관리
- Perception과 Generator 연결
- 입력 데이터 전처리 및 출력 데이터 후처리
Loss
- Path Distance Loss
- 예측 경로와 실제 경로 간의 Hausdorff distance
- Last Pose Loss
- 마지막 위치에 대한 MSE Loss
- Traversability loss
use_traversability 가 True이면
def _local_collision(self, yhat, local_map):
# yhat: 생성된 궤적의 waypoints (B,N,2 shape)
# local_map: 주행 가능성 맵 (B,W,H shape)
# waypoint 좌표를 픽셀 좌표로 변환
pixel_yhat = yhat / self.map_resolution + self.map_range
pixel_yhat = pixel_yhat.to(torch.int)
for i in range(By):
# local_map에서 0보다 큰 값(장애물이나 주행 불가능 영역)의 위치를 찾음
map_indices = torch.stack(torch.where(local_map[i] > 0), dim=1)
# 각 waypoint와 주행 불가능 영역 간의 거리 계산
loss, traversability = self._cropped_distance(pixel_yhat[i], map_indices)데이터셋에 traversability map이 binary하게 저장되어 있으니까 그걸 그냥 간단하게 비교함.
추가로, _local_collision 함수는 배치 단위로 traversability를 검사하고 _cropped_distance는 단일 궤적에 대해서 계산함.
'논문 리뷰' 카테고리의 다른 글
Contents
소중한 공감 감사합니다