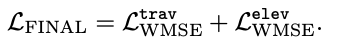고속의 오프로드 환경에서의 자율 주행은 로봇이 온보드 센서만을 사용해서 주변 환경을 종합적으로 이해해야 한다. 오프로드 환경이 가하는 극한의 조건은 이미지 품질 저하와 함께 고속 주행 시 LiDAR 센싱에서 얻을 수 있는 제한적이고 희박한 기하학적 정보를 야기할 수 있다. 본 연구에서는 카메라와 LiDAR 센서 입력으로부터 직접 지형 주행 가능성과 고도를 예측할 수 있는 새로운 프레임워크인 RoadRunner를 제시한다. RoadRunner는 센서 정보를 융합하여 신뢰할 수 있는 자율 주행을 가능하게 하며, 낮은 지연 시간으로 작동하면서 지형의 기하학과 주행 가능성에 대해 문맥적으로 정보를 제공하는 예측(Contextually informed predictions)을 생성한다. 수작업으로 만든 의미론적 클래스를 분류하고 Heuristic을 사용하여 Traversability score를 예측하는 기존 방법들과 달리, 본 논문에서 제시하는 방법은 Traversability를 직접 예측한다. 이는 Self-supervised 방식으로 사후에 자동으로 생성될 수 있는 label로 훈련된다. RoadRunner 네트워크 아키텍쳐는 LiDAR와 카메라 정보를 common Bird's eye view로 통합하는 방식을 이용한다.
RoadRunner는 시스템 지연 시간을 500ms에서 140ms로 약 4배 개선하면서도 Traversability cost와 Elevation map 예측 정확도를 향상시켰다.
Introduction
어떤 동물들은 32km/h의 속도로 복잡한 오프로드 지형을 가로지를 수 있다. 비구조화된 오프로드 환경에서 고속 운행을 가능하게 하는 자율 지상 차량에 필요한 인지 능력의 측면에서 그런 달리는 동물(RoadRunner)를 모방할 필요가 있다. 고속 주행 시 안전을 확보하는 핵심 요소 중 하나는 로봇이 안전하게 주행할 수 있는 영역을 평가하는 것이다. 이 평가는 Traversability Estimation이라고 알려져 있으며, 목표는 로봇이 지형을 주행할 때 위험 정도를 추정하는 것이다. 이 수치는 로봇의 하드웨어, 제어 시스템, 지형의 기하학적 특성 등에 따라 달라질 수 있다.
복잡하고 비구조화된 오프로드 환경은 자율 지상 차량이 올바르게 평가해야 할 다양한 장애물과 기타 잠재적인 위험들을 가지고 있다. 또한 고속에서는 짧은 반응 시간이 필요하며, 잠재적인 위험을 먼 거리에서 식별해야 안전을 보장할 수 있다. 더욱이 LiDAR와 카메라와 같은 온보드 센서가 제한된 업데이트 속도로만 정보를 제공할 수 있고, 먼 거리에서 증가하는 본질적인 희소성으로 인해 제한된 시야만을 인식할 수 있기 때문에 환경에 대한 부분적인 관찰만 가능하다. 또한 오프로드 주행을 고려할 때 로봇이 처음으로 환경에 배치되거나 (우주 탐사) 계절적인 변화로 인해 환경이 크게 변했을 수 있기 때문에 고해상도 지도 정보에만 의존할 수는 없다. 게다가 먼지, 오염, 안개, 비와 같은 극한 조건은 오프로드 환경에서 흔하며 이는 LiDAR센서의 인식 성능을 저하시킨다. 결과적으로 주행 가능성 추정 시스템은 고속에서 오프로드 환경 내 주행을 가능하게 하기 위해 이런 모든 과제를 해결해야 한다.
본 논문의 주요 기여점은 다음과 같다.
1. 다중 LiDAR와 다중 카메라 데이터로부터 낮은 지연 시간으로 Traversability cost와 Elevation map을 동시에 예측할 수 있는 새로운 아키텍쳐(RoadRunner) 제안. 2. 네트워크를 Self-supervised 방식으로 훈련하기 위해 사후 temporal data를 사용하여 pseudo-ground truth elevation map과 traversability cost를 생성하는 프레임워크 제안 3. 오프로드 자율주행 소프트웨어 스택 중 하나인 NASA 제트 추진 연구소의 오프로드 자율 주행 연구 스택 X-racer에 대한 overview 제시. 4. 실제 현장 테스트 데이터로 RoadRunner 아키텍쳐 평가 및 기존 아키텍쳐와 비교
RoadRunner는 시각적 및 기하학적 데이터를 활용하여 훈련 데이터 생성에 사용된 X-Racer의 고도 매핑 및 주행 가능성 추정을 능가하고 있다. 또한 학습된 context를 기반으로 누락된 Elevation 및 Traversability 정보를 예측할 수 있다. 주행 가능성 감지에도 같은 원리가 적용되어 더 먼 거리에서 장애물을 감지할 수 있었다.
RoadRunner는 X-Racer과 비교하여 주행 가능성 비용 추정을 MSE에서 52.3%, Elevation map 추정을 MAE에서 36% 개선하면서도 기존 소프트웨어 스택에 비해 지연 시간을 4배 감소시킴을 입증하였다.
Related Work
A. Traversability Estimation for Off-Road Driving
지형의 주행 가능성은 지형의 기하학과 강성, 마찰 등과 같은 물리적 특성에 의존한다. 사용 중인 특정 로봇 시스템, 적용된 Control 전략, 그리고 지형과 상호작용하는 동안의 로봇의 상태와 같은 여러 다른 요인들이 주행 가능성에 영향을 미친다. 예를 들어, 서로 다른 로봇(hardware and control dependence)은 다양한 속도로 주행할 때(state dependence) 서로 다른 장애물을 극복할 수 있다. 본 연구에서는 이런 다변량 주행 가능성 관점을 단순화하고, 주행 가능성을 주어진 지형을 극복하는 데 필요한 행동 가능성/위험을 확률 분포로 모델링한다. 전체 주행 가능성을 더 해석 가능하게(interpretable) 만들기 위해, 우리는 Conditional Value at Risk(CVaR) 메트릭을 사용한다. Monotonic, Subadditive, Homogeneous, Travesational invariant라는 특성을 갖는 일관된 위험 메트릭인 CVaR은 주어진 지형과 관련된 위험 분포의 다른 부분을 강조할 수 있게 해준다.
[15]는 Onroad 주행을 위해 저해상도 카메라 이미지에서 온라인으로 조향 명령을 예측하기 위해 MLP를 훈련시켜 시연 과정으로부터 학습하는 방식을 선구적으로 시작했다. 당시 개발된 인식 시스템은 주로 휴리스틱에 기반했기 때문에 복잡한 오프로드 영역을 일반화하는 데 실패했다.
1) Traversability from Semantics
현대의 딥러닝 방법은 이미지와 포인트 클라우드 데이터에서 의미론적으로 장면을 이해하는 것에 탁월한 성능을 보이고 있다. 일반적으로 식별된 Semantic class들은 지도 표현(Map representation)으로 융합되고, 이는 Traversability score와 연관된다. 주목할 만한 점은 RUGD, Rellis-3D 또는 Freiburg Forest와 같은 데이터셋이 고품질의 annotated semantic을 제공하지만, 크기와 다양성에 제한이 있어 일반화하기가 어렵다.
우리와 연구와 가장 관련이 있는 것은 TerrainNet으로, 환경을 지면과 천장으로 모델링하며 각 층은 관련한 Semantic을 포함한다. Geometry와 Semantic은 RGB 및 깊이 카메라 이미지를 입력으로 받는 신경망에 의해 예측된다.
2) Traversability from Self-Supervision
Scene semantic에 기반한 Traversability estimation은 일반적으로 비용이 많이 든다. Self-supervised 방식으로 작동하는 방법들은 manual annotation에 의존하지 않고 training 데이터셋을 생성함으로써 이러한 한계를 극복하고자 한다. 대신 다른 센서 모달리티의 정보나 로봇과 환경의 상호작용을 활용한다.
3) Other Traversability Estimation Approaches
기하학적 주행 가능성을 평가하기 위한 모델 기반 접근법은 지속적으로 연구되어 왔다. 특히 Wheeled robot은 바퀴와 지형 간의 상호작용이 더 복잡한 다족 시스템에 비해 쉽게 정의될 수 있다. 이를 위해 최근 연구들은 포인트 클라우드 데이터, 메쉬 데이터 또는 Elevation map의 분석에 의존한다. 반면에 데이터 기반 접근법은 시뮬레이션을 사용하여 trial-and-error 방식으로 데이터를 수집해 Wheeled robot이나 legged robot의 주행 가능성을 추정한다.
B. Learning Semantics in BEV Representation
Method
A. Problem Statement
RoadRunner는 다중 카메라와 다중 LiDAR르 사용하여 vehicle-centric elevation과 travesability cost map을 생성한다.
먼저, 사용 가능한 기하학적 정보의 밀도에 비례하는 신뢰성 지도(Reliability map)가 계산된다. 예를 들어, 고도 지도 내의 특정 영역에 대한 기하학적 관찰이 불충분할 경우, 이 셀들에 대한 추정은 덜 신뢰할 수 있는 것으로 간주된다. 또한 Elevation map은 경사, 곡률, 거칠기, Positive 혹은 Negative 장애물에 대한 위험을 추출할 수 있다.
지형-바퀴 상호작용과 관련된 위험을 설명하는 Final wheel risksms CVaR로 주어진다. 이하에서는 Wheel risk의 CVaR을 주행 가능성이라고 부르며, 0은 안전하게 주행 가능함을, 1은 안전하지 않음을 나타낸다.
5) Trajectory Planning
20cm 해상도의 100m x 100m 크기의 CVaR wheel risk 지도는 고속에서 장애물 회피를 담당하는 모델 예측 경로 적분 계획기 (Model Predictive Path Integral planner)에 제공된다. Planner는 향후 5초까지, 30Hz로 작동한다. Planner는 차량의 동역학 모델을 알 수 있으며, 경로의 부드러움을 추구하면서도 목표까지의 시간을 최소화한다.
D. RoadRunner Hindsight Traversability Generation
E. RoadRunner Network
RoadRunner는 특별히 고속 오프로드 주행을 가능하게 하도록 설계되었다. 이를 위해 RoadRunner는 140ms의 낮은 지연 시간으로 작동해야 하며, 최대 20m/s의 속도로 주행할 때 매 3m 마다 새로운 환경 예측을 제공할 수 있어야 한다. 따라서 우리는 100m x 100m의 예측 범위를 선택했으며, 이는 고속 처리에 적합하다.
* 좀 이해가 잘 안 되는 부분 :
... We also directly operate on single LiDAR scans rather than a fused map representation. This makes RoadRunner less susceptible to sparse geometric information at high speeds. The number of geometric points per LiDAR point cloud is nearly independent of the vehicle velocity. This is not the case when operating on an accumulated map representation, where the density of geometric information strongly correlates with the vehicle velocity. ...
Q1. fused map representation보다 single LiDAR scan이 고속에서 더 유리한 (?) 이유 ?
1) Preprocessing and Feature Extraction
RoadRunner 네트워크는 오픈소스로 사용 가능한 Lift Splat Shoot, PointPillars, BEVFusion을 기반으로 하며, 이전의 두 방법을 결합하여 개선하였다.
이미지 timestamp t는 차량 중심 그리드 맵의 reference frame을 결정한다. 각 LiDAR의 최신 측정값은 motion compensate되고, base frame으로 변환된다. 각 카메라 이미지에서 EfficientNet을 사용하여 특징을 추출하며, 이는 입력 크기를 16배 downsampling하여 각 이미지 k에 해당하는 특징 맵 (32x24x328)을 생성한다.
병합된 포인트 클라우드는 target grid map과 동일한 그리드 구성 (100m x 100m, 20cm 해상도)을 가진 PointPillars 백본을 통과하며, 이는 포인트 클라우드 특징 맵을 생성한다. 또한 Elevation은 먼저 0.05 인자로 scaling한 후 [-1,1] 사이로 clipping하여 정규화된다.
2) Lifting
카메라 이미지 평면에서 3D 공간으로의 특징 Lifting은 핀홀 카메라 모델을 사용하여 이루어진다. 각 픽셀의 ray를 따라 3D 공간에 동일한 간격으로 점들의 집합이 분포되어 특징점 집합을 형성한다. 특징점들은 target grid map과 동일한 차원과 해상도를 가진 grid map cell로 래스터화된다.
3) Multi-Modal Fusion
3종의 Feature map (img, pcd, elevation)은 multi-modal feature map으로 concatenate된다. 현재 LiDAR 스캔으로 볼 수 없는 영역에 대해서도 이전에 얻은 Elevation 정보를 네트워크에 제공함으로써 전체적인 지형 이해를 유지하고 개선한다. 두 개의 분리된 디코더 네트워크는 elevation과 traversability estimation을 하기 위해서 학습된다. 각각의 디코더는 convolution, batch norm, ReLU activation 레이어를 가지고 있다.
4) RoadRunner Loss
RoadRunner를 학습하기 위해 Weighted Mean Squared Error를 사용한다.
weighting factor는 target grid cell의 value에 의해 계산된다.